
In this chapter, we:
•
Survey the many different types of software and hardware web servers.
•
Explain how web servers process HTTP transactions, step by step.
1. Web Servers Come in All Shapes and Sizes
•
A web server processes HTTP requests and serves responses.
•
The term “web server” can refer either to web server software or to the particular device or computer dedicated to serving the web pages.
•
Web servers comes in all flavors, shapes, and sizes.
•
But whatever the functional differences, all web servers receive HTTP requests for resources and serve content back to the clients (look back to Figure 1-5).
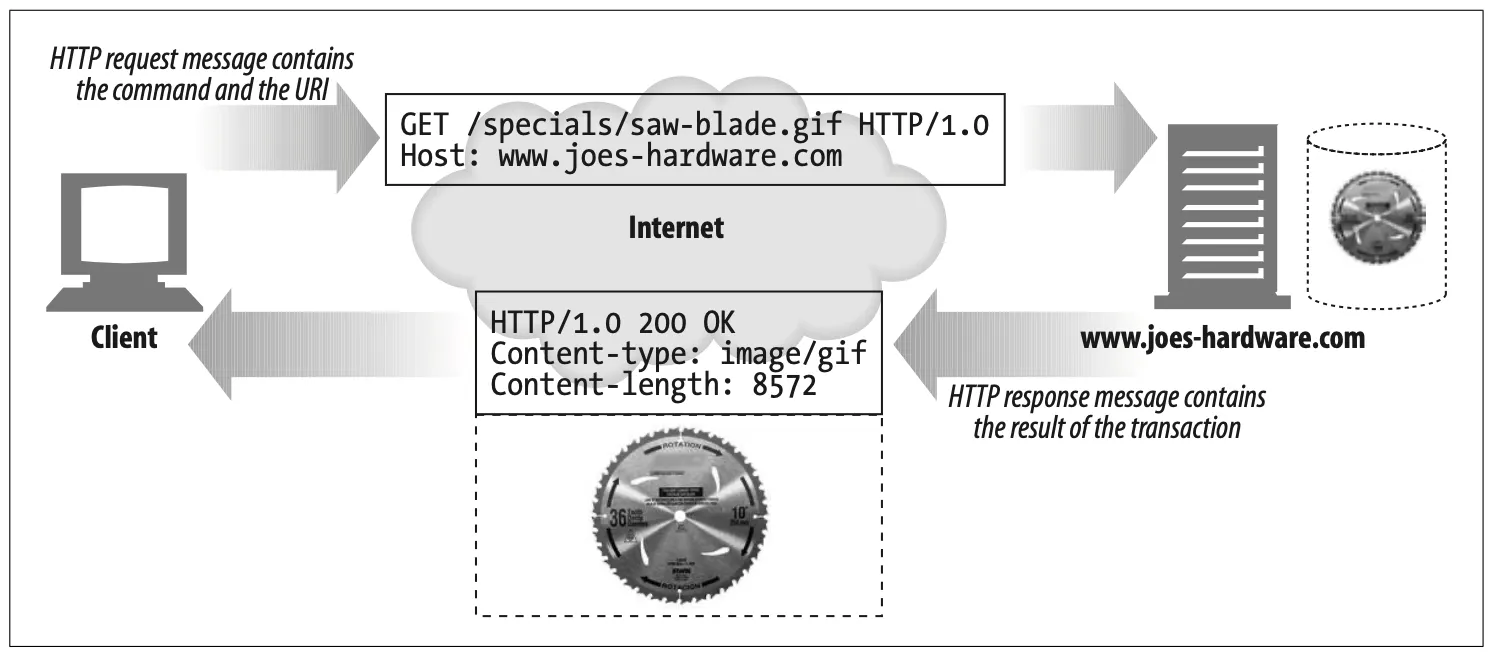
Figure 1-5. HTTP transactions consist of request and response messages
1.1. Web Server Implementations
•
Web servers implement HTTP and the related TCP connection handling.
•
They also manage the resources served by the web server
•
And provide administrative features to configure, control, and enhance the web server.
•
The web server logic shares responsi- bilities for managing TCP connections with the operating system.
•
Web servers are available in many forms:
◦
You can install and run general-purpose software web servers on standard com
puter systems.
◦
If you don’t want the hassle of installing software, you can purchase a webserver appliance, in which the software comes preinstalled and preconfigured on a
computer, often in a snazzy-looking chassis.
◦
Some companies even offer embedded web servers implemented in a small number of computer chips, making them perfect administration consoles for consumer devices.
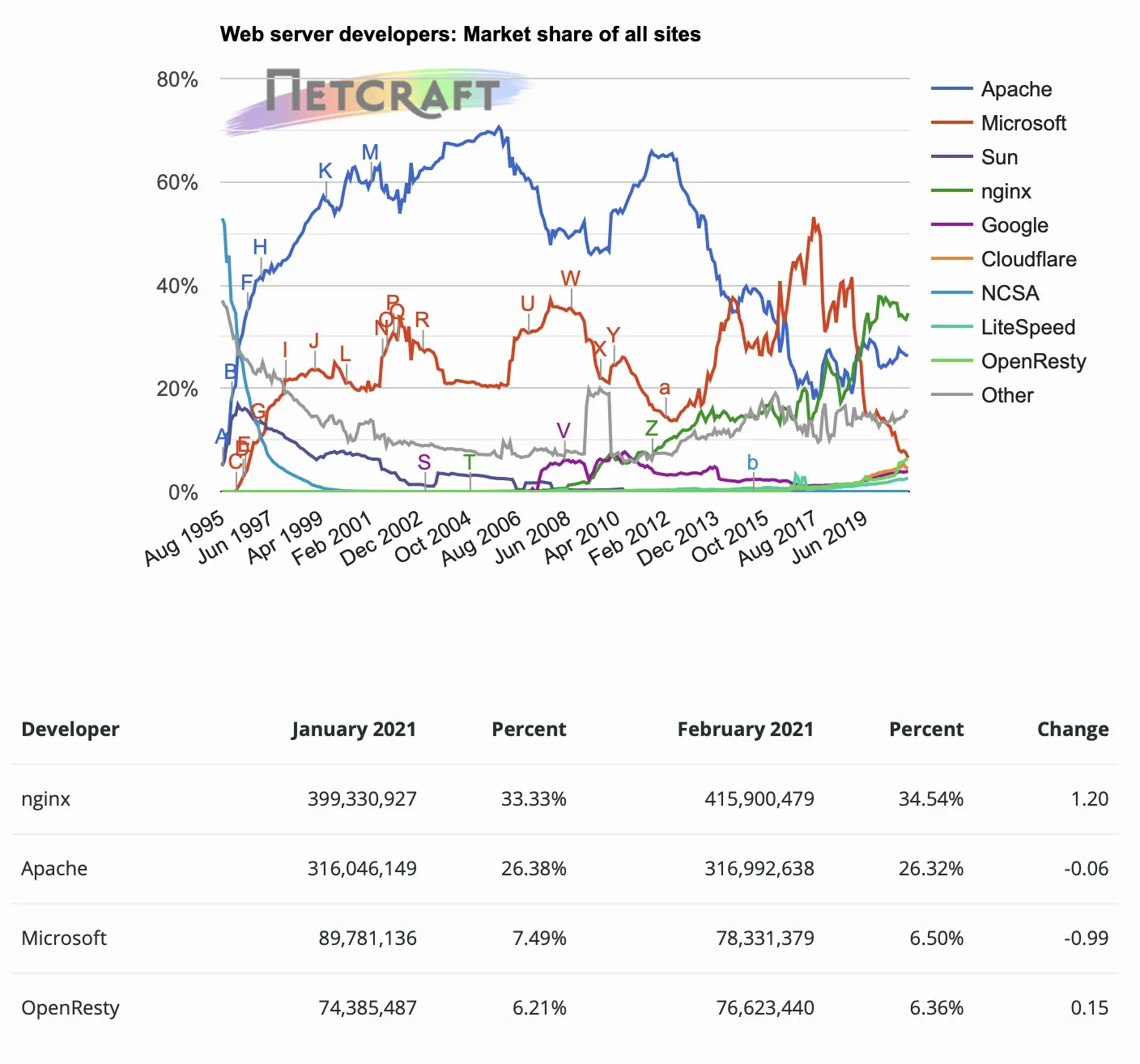
1.2. General-Purpose Software Web Servers
•
General-purpose software web servers run on standard, network-enabled computer systems.
◦
open source software such as Apache or commercial software such as Microsoft’s web servers.
•
Web server software is available for just about every computer and operating system.
1.3. Embedded Web Servers
•
Embedded servers are tiny web servers intended to be embedded into consumer products (e.g., printers or home appliances).
•
Embedded web servers allow users to administer their consumer devices using a convenient web browser interface.
•
Some embedded web servers can even be implemented in less than one square inch, but they usually offer a minimal feature set.
2. A Minimal Perl Web Server
Skip
3. What Real Web Servers Do
•
State-of- the-art commercial web servers are complicated, but they do perform several common tasks, as shown in Figure 5-3:
1.
Set up connection—accept a client connection, or close if the client is unwanted.
2.
Receive request—read an HTTP request message from the network.
3.
Process request—interpret the request message and take action.
4.
Access resource—access the resource specified in the message.
5.
Construct response—create the HTTP response message with the right headers.
6.
Send response—send the response back to the client.
7.
Log transaction—place notes about the completed transaction in a log file.
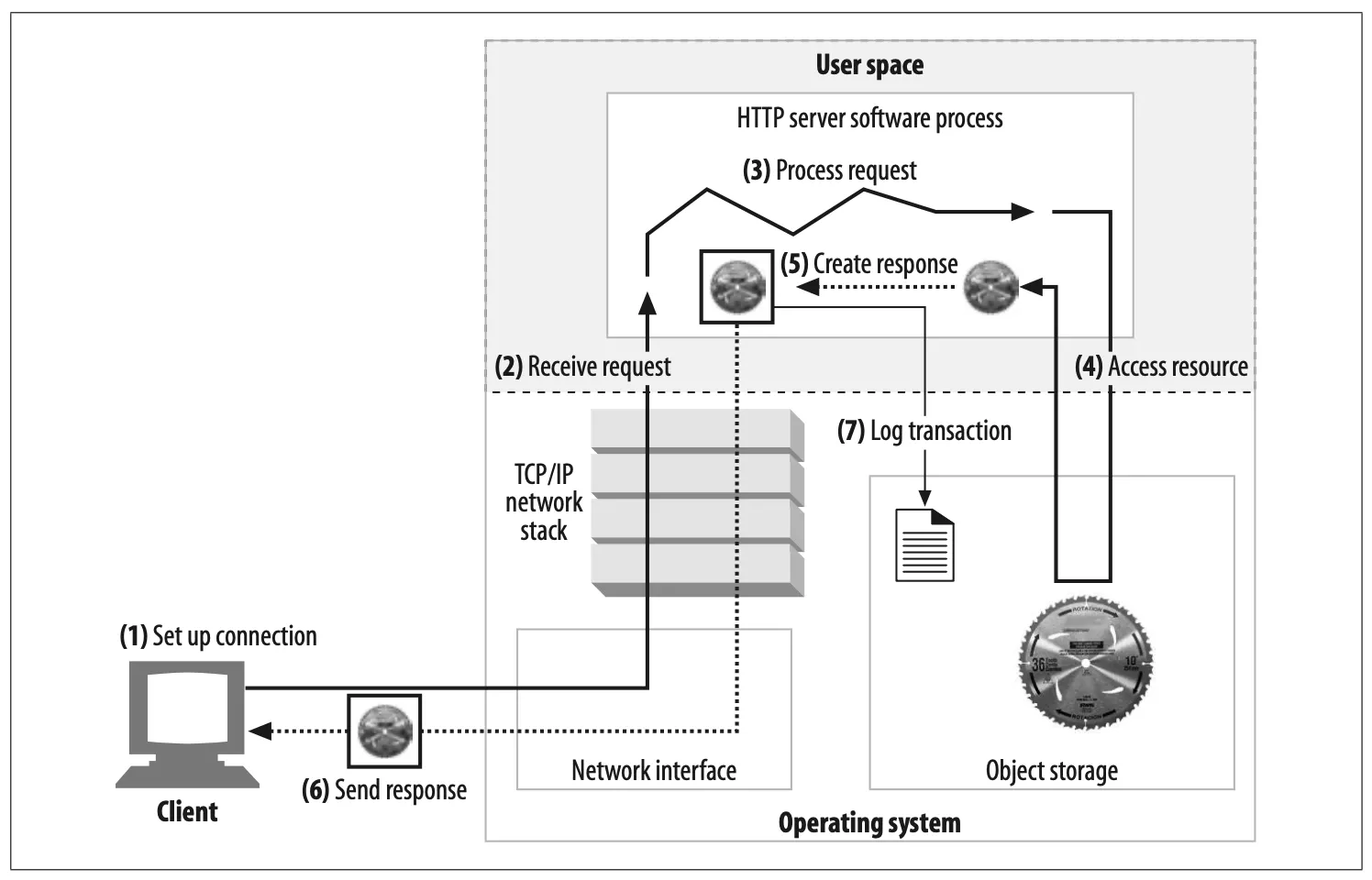
Figure 5-3. Steps of a basic web server request
4. Step 1: Accepting Client Connections
•
If a client already has a persistent connection open to the server, it can use that connection to send its request.
•
Otherwise, the client needs to open a new connection to the server.
4.1. Handling New Connections
•
When a client requests a TCP connection to the web server, the web server establish-es the connection and determines which client is on the other side of the connection, extracting the IP address from the TCP connection.*
•
Once a new connection is established and accepted, the server adds the new connection to its list of existing web server connections and prepares to watch for data on the connection.
•
The web server is free to reject and immediately close any connection.
•
Some web servers close connections because the client IP address or hostname is unauthorized or is a known malicious client.
4.2. Client Hostname Identification
•
Most web servers can be configured to convert client IP addresses into client host- names, using “reverse DNS”.
•
Web servers can use the client hostname for detailed access control and logging.
•
Be warned that hostname lookups can take a very long time, slowing down web transactions.
Example
5. Step 2: Receiving Request Messages
•
As the data arrives on connections, the web server reads out the data from the network connection and parses out the pieces of the request message (Figure 5-5).
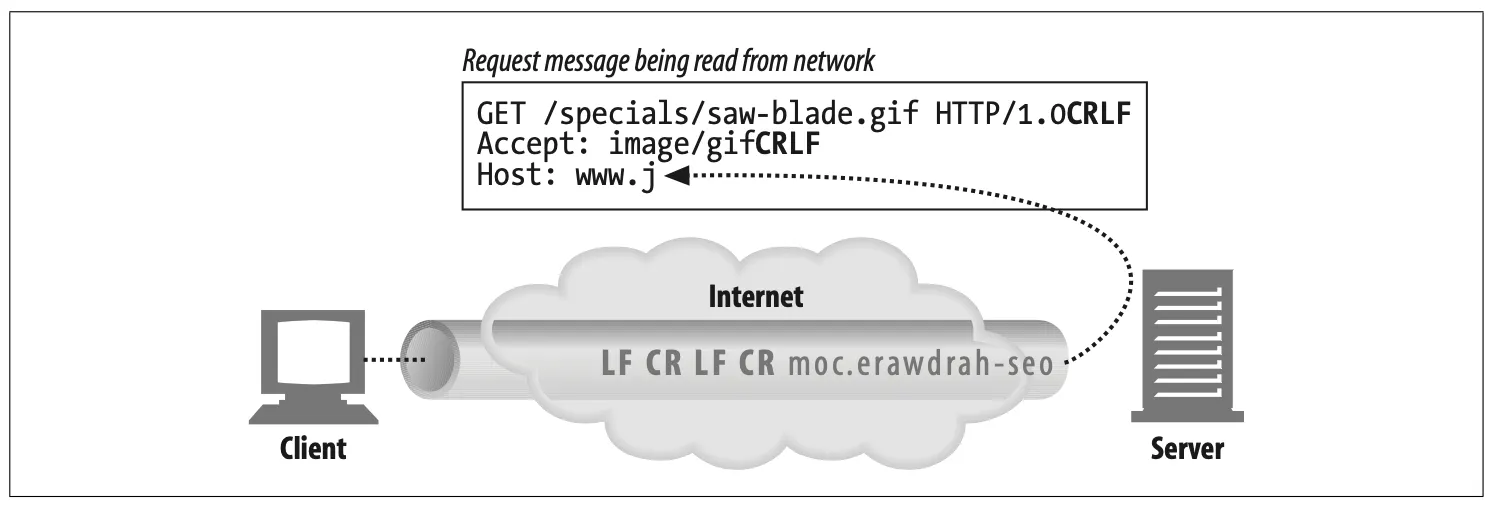
Figure 5-5. Reading a request message from a connection
•
When parsing the request message, the web server:
◦
Parses the request line looking for the request method, the specified resource
identifier (URI), and the version number, each separated by a single space, and
ending with a carriage-return line-feed (CRLF) sequence
◦
Reads the message headers, each ending in CRLF
◦
Detects the end-of-headers blank line, ending in CRLF (if present)
◦
Reads the request body, if any (length specified by the Content-Length header)
•
When parsing request messages, web servers receive input data erratically from the network.
•
The network connection can stall at any point.
•
The web server needs to read data from the network and temporarily store the partial message data in memory until it receives enough data to parse it and make sense of it.
5.1. Internal Representations of Messages
•
Some web servers also store the request messages in internal data structures that make the message easy to manipulate.
•
For example, the data structure might contain pointers and lengths of each piece of the request message, and the headers might be stored in a fast lookup table so the specific values of particular headers can be accessed quickly (Figure 5-6).
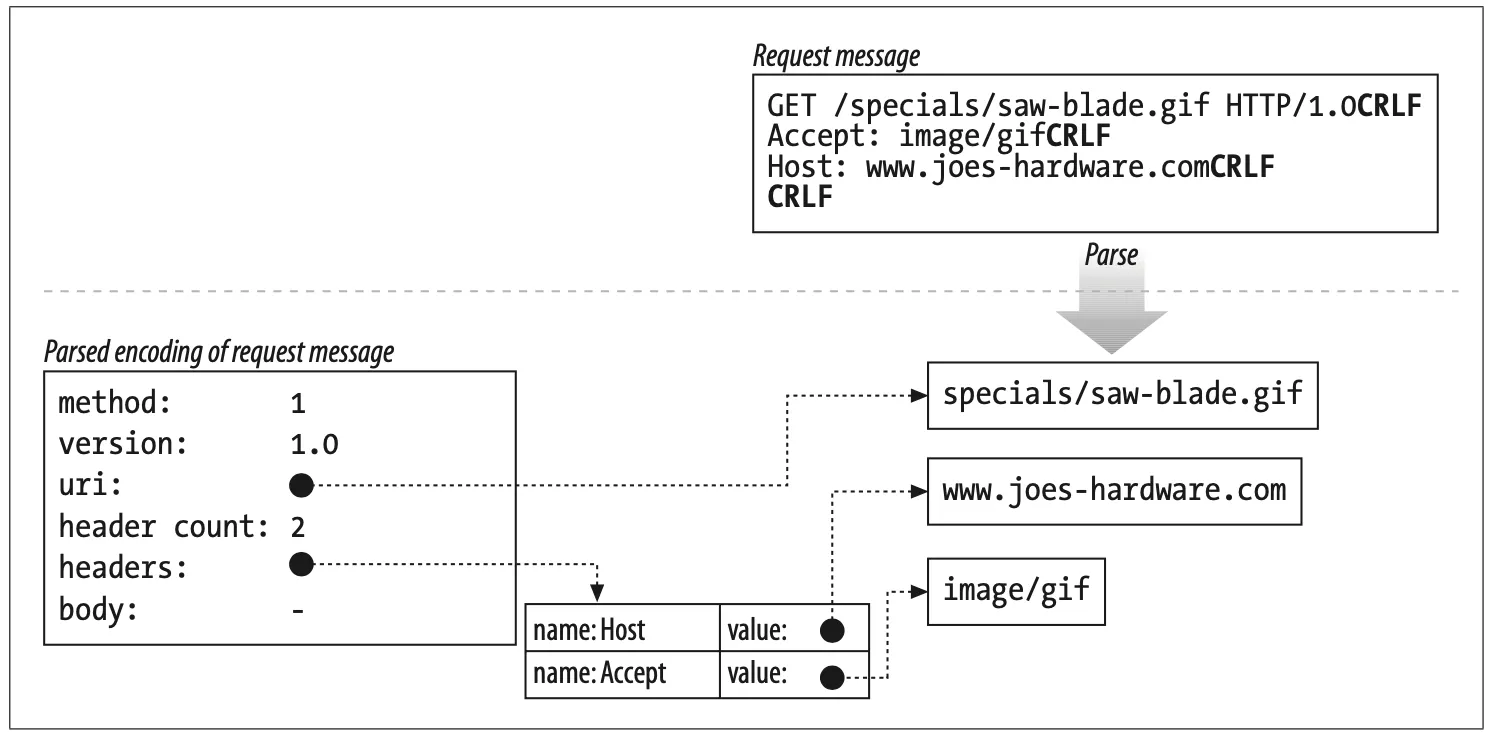
Figure 5-6. Parsing a request message into a convenient internal representation
5.2. Connection Input/Output Processing Architectures
•
High-performance web servers support thousands of simultaneous connections.
•
Some of these connections may be sending requests rapidly to the web server, while other connections trickle requests slowly or infrequently, and still others are idle, waiting quietly for some future activity.
•
Different web server architectures service requests in different ways, as Figure 5-7 illustrates:
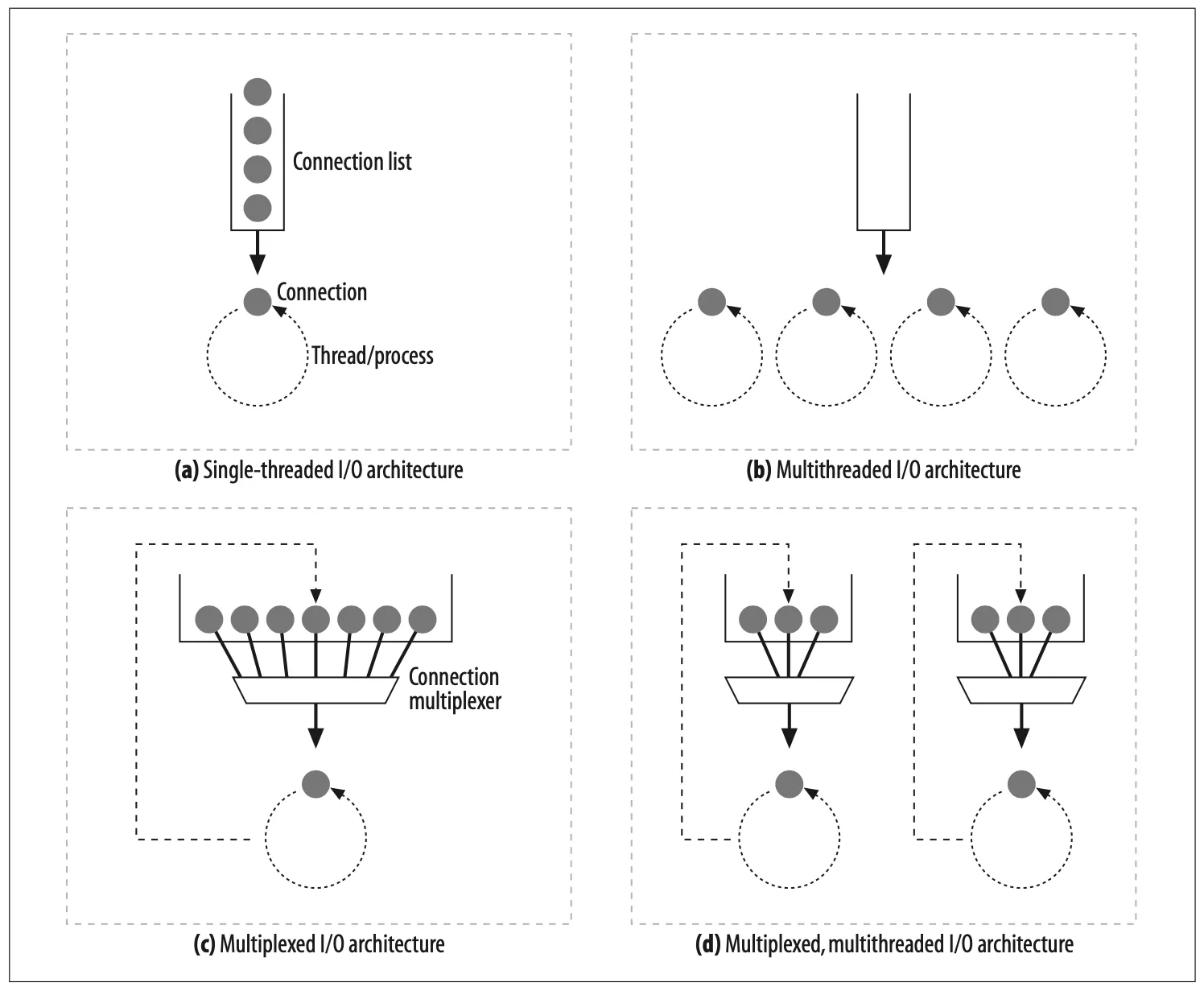
Figure 5-7. Web server input/output architectures
Single-threaded web servers (Figure 5-7a)
Single-threaded web servers process one request at a time until completion. When the transaction is complete, the next connection is processed. This architecture is simple to implement, but during processing, all the other connections are ignored. This creates serious performance problems and is appropriate only for low-load servers and diagnostic tools like type-o-serve.
Multiprocess and multithreaded web servers (Figure 5-7b)
Multiprocess and multithreaded web servers dedicate multiple processes or higher-efficiency threads to process requests simultaneously. The resulting number of processes or threads may consume too much memory or system resources. Thus, many multithreaded web servers put a limit on the maximum number of threads/processes.
Multiplexed I/O servers (Figure 5-7c)
To support large numbers of connections, many web servers adopt multiplexed architectures. In a multiplexed architecture, all the connections are simultaneously watched for activity. When a connection changes state (e.g., when data becomes available or an error condition occurs), a small amount of processing is performed on the connection; when that processing is complete, the connection is returned to the open connection list for the next change in state. Work is done on a connection only when there is something to be done; threads and processes are not tied up waiting on idle connections.
Multiplexed multithreaded web servers (Figure 5-7d)
Some systems combine multithreading and multiplexing to take advantage of multiple CPUs in the computer platform. Multiple threads (often one per physical processor) each watch the open connections (or a subset of the open connections) and perform a small amount of work on each connection.
6. Step 3: Processing Requests
•
Some methods (e.g., POST) require entity body data in the request message. Other
methods (e.g., OPTIONS) allow a request body but don’t require one. A few methods (e.g., GET) forbid entity body data in request messages.
•
We won’t talk about request processing here, because it’s the subject of most of the
chapters in the rest of this book!
7. Step 4: Mapping and Accessing Resources
•
Web servers deliver precreated content, such as HTML pages or JPEG images, as well as dynamic content from resource-generating applications running on the servers.
•
Before the web server can deliver content to the client, it needs to identify the source
of the content, by mapping the URI from the request message to the proper content
or content generator on the web server.
7.1. Docroots
•
The simplest form of resource mapping uses the request URI to name a file in the web server’s filesystem.
•
Typically, a special folder in the web server filesystem is reserved for web content. This folder is called the document root, or docroot.

Figure 5-8. Mapping request URI to local web server resource
•
To set the document root for an Apache web server, add a DocumentRoot line to the
httpd.conf configuration file: DocumentRoot /usr/local/httpd/files
Virtaully hosted docroots
•
Virtually hosted web servers host multiple web sites on the same web server, giving each site its own distinct document root on the server.
•
A virtually hosted web server identifies the correct document root to use from the IP address or hostname in the URI or the Host header. This way, two web sites hosted on the same web server can have completely distinct content, even if the request URIs are identical.
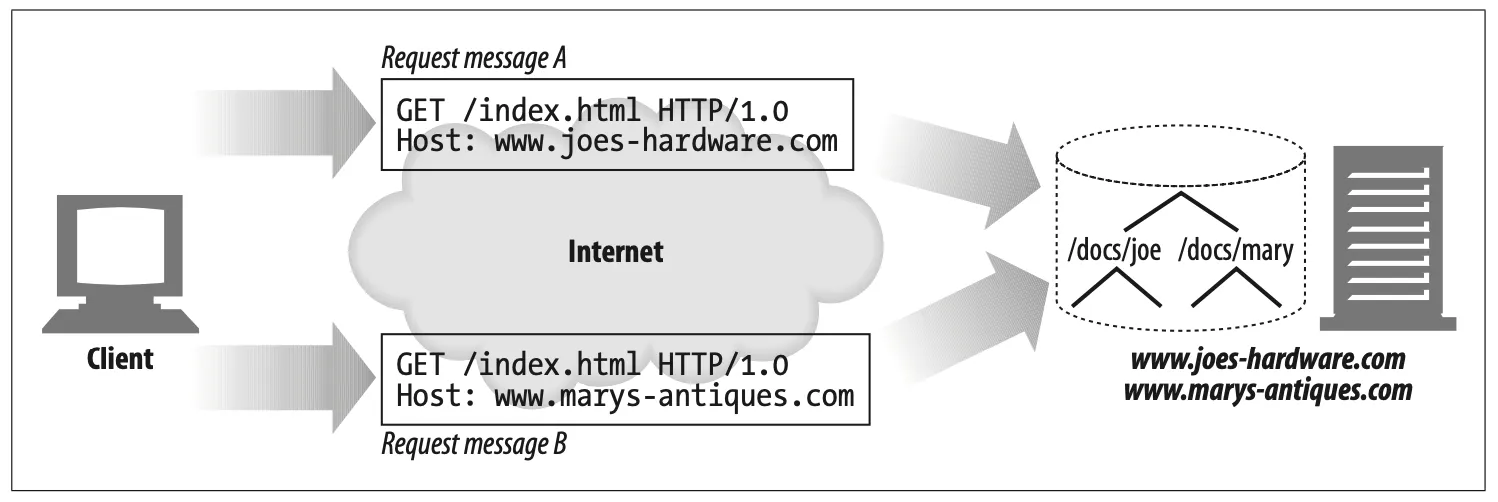
Figure 5-9. Different docroots for virtually hosted requests
User home directory docroots
•
Another common use of docroots gives people private web sites on a web server.
•
A typical convention maps URIs whose paths begin with a slash and tilde (/~) followed by a username to a private document root for that user.
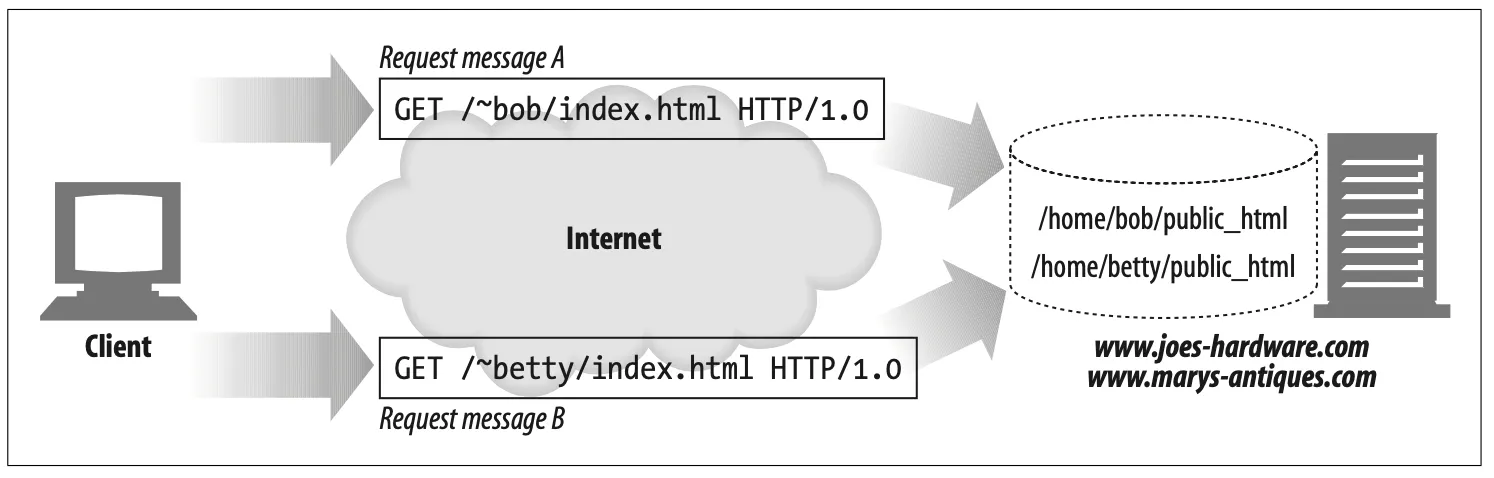
Figure 5-10. Different docroots for different users
7.2. Directory Listings
•
A web server can receive requests for directory URLs, where the path resolves to a directory, not a file. Most web servers can be configured to take a few different actions when a client requests a directory URL:
◦
Return an error.
Return a special, default, “index file” instead of the directory.
Scan the directory, and return an HTML page containing the contents.
7.3. Dynamic Content Resource Mapping
•
Web servers also can map URIs to dynamic resources—that is, to programs that generate content on demand (Figure 5-11).
•
In fact, a whole class of web servers called application servers connect web servers to sophisticated backend applications.
•
The web server needs to be able to tell when a resource is a dynamic resource, where the dynamic content generator program is located, and how to run the program.
•
Most web servers provide basic mechanisms to identify and map dynamic resources.
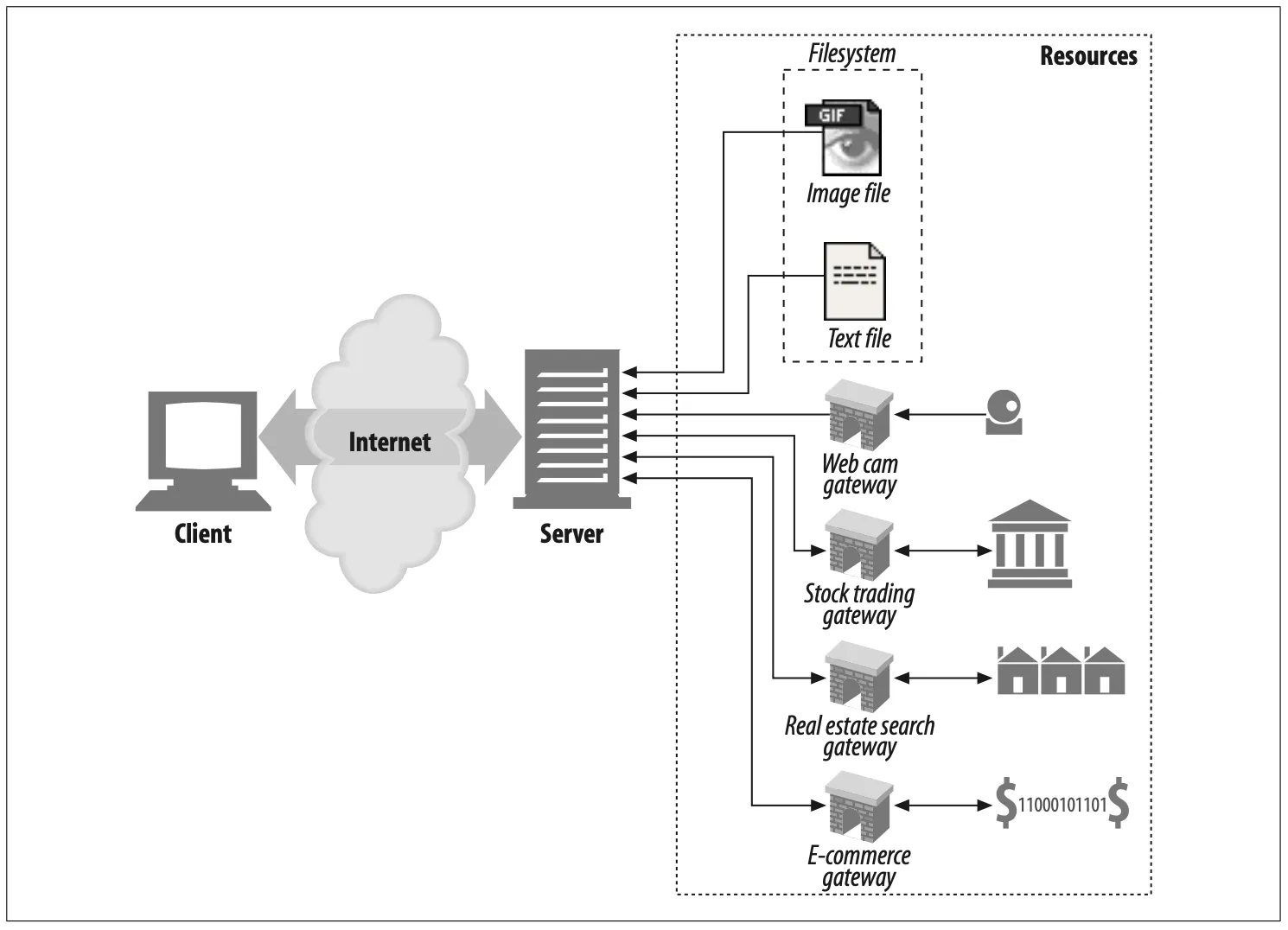
Figure 5-11. A web server can serve static resources as well as dynamic resources
•
Apache lets you map URI pathname components into executable program directories. When a server receives a request for a URI with an executable path component, it attempts to execute a program in a corresponding server directory.
For example
•
CGI is an early, simple, and popular interface for executing server-side applications.
•
Modern application servers have more powerful and efficient server-side dynamic content support, including Microsoft’s Active Server Pages and Java servlets.
7.4. Server-Side Includes (SSI)
•
Many web servers also provide support for server-side includes.
•
If a resource is flagged as containing server-side includes, the server processes the resource contents before sending them to the client.
•
The contents are scanned for certain special patterns (often contained inside special HTML comments), which can be variable names or embedded scripts.
•
The special patterns are replaced with the values of variables or the output of executable scripts. This is an easy way to create dynamic content.
7.5. Access Controls
•
Web servers also can assign access controls to particular resources.
•
When a request arrives for an access-controlled resource, the web server can control access based on the IP address of the client, or it can issue a password challenge to get access to the resource.
Refer to Chapter 12 for more information about HTTP authentication.
8. Step 5: Building Responses
Once the web server has identified the resource, it performs the action described in the request method and returns the response message.
8.1. Response Entities
If the transaction generated a response body, the content is sent back with the
response message. If there was a body, the response message usually contains:
•
A Content-Type header, describing the MIME type of the response body
•
A Content-Length header, describing the size of the response body
•
The actual message body content
8.2. MIME Typing
•
The web server is responsible for determining the MIME type of the response body. There are many ways to configure servers to associate MIME types with resources:
The ways assoicating MIME type
8.3. Redirection
•
A web server can redirect the browser to go elsewhere to perform the request.
•
A redirection response is indicated by a 3XX return code.
•
The Location response header contains a URI for the new or preferred location of the content.
•
Redirects are useful for:
Permanently moved resources
A resource might have been moved to a new location, or otherwise renamed, giving it a new URL. The web server can tell the client that the resource has been renamed, and the client can update any bookmarks, etc. before fetching the resource from its new location. The status code 301 Moved Permanently is used for this kind of redirect.
Temporarily moved resources
If a resource is temporarily moved or renamed, the server may want to redirect the client to the new location. But, because the renaming is temporary, the server wants the client to come back with the old URL in the future and not to update any bookmarks. The status codes 303 See Other and 307 Temporary Redirect are used for this kind of redirect.
URL augmentation(?)
Servers often use redirects to rewrite URLs, often to embed context. When the request arrives, the server generates a new URL containing embedded state information and redirects the user to this new URL.* The client follows the redirect, reissuing the request, but now including the full, state-augmented URL. This is a useful way of maintaining state across transactions. The status codes 303 See Other and 307 Temporary Redirect are used for this kind of redirect.
Load balancing
If an overloaded server gets a request, the server can redirect the client to a less heavily loaded server. The status codes 303 See Other and 307 Temporary Redi- rect are used for this kind of redirect.
Server affinity
Web servers may have local information for certain users; a server can redirect the client to a server that contains information about the client. The status codes 303 See Other and 307 Temporary Redirect are used for this kind of redirect.
Canonicalizing directory names
When a client requests a URI for a directory name without a trailing slash, most web servers redirect the client to a URI with the slash added, so that relative links work correctly.
9. Step 6: Sending Responses
•
Web servers face similar issues sending data across connections as they do receiving.
•
The server needs to keep track of the connection state and handle persistent connections with special care.
•
For nonpersistent connections, the server is expected to close its side of the connection when the entire message is sent.
•
For persistent connections, the connection may stay open, in which case the server needs to be extra cautious to compute the Content-Length header correctly, or the client will have no way of knowing when a response ends (see Chapter 4).
10. Step 7: Logging
•
Finally, when a transaction is complete, the web server notes an entry into a log file, describing the transaction performed.
•
Most web servers provide several configurable forms of logging. Refer to Chapter 21 for more details.
