
If HTTP is the Internet's courier, HTTP messages are the pacakages it uses to move things around. In Chapter 1, we showed how HTTP programs send each other messages to get work done. This chapter tells you about HTTP messages — how to ceate them and how to understand them. After reading this chapter, you'll know most of what you need to know to write your own HTTP applications. In prticular, you'll understand:
•
How messages flow
•
The three parts of HTTP messages (start line, headers, and entity body)
•
The difference between request and response messages
•
The various functions (methods) that request messages support
•
The various status codes that are returned with response messages
•
What the various HTTP headers do
1. The Flow of Messages
HTTP messages are the blocks of data sent between HTTP application. These blocks of data begin with some text meta-information decribing the message contents and meaning, followed by optional data. These messages flow between clients, servers, and proxies. The terms "inbound", "outbound", "upstream", and "downstream" describe message direction.
1.1. Messages Commute Inbound to the Origin Server
HTTP uses the terms inbound and outbound to describe transactional direction. Messages travel inbound to the origin server, and when their work is done, they travel outbound back to the user agent (see Figure 3-1).

Figure 3-1. Messages travel inbound to the origin server and outbound back to the client
1.2. Messages Flow Downstream
HTTP messages flow like rivers. All message flow downstream, regardless of whether they are request messages or responses message (see Figure 3-2). The sender of any message is upstream of the receiver. In Figure 3-2, proxy 1 is upstream of proxy 3 for the request but downstream of proxy 3 for the response.
The terms "upstream" and "downstream" relate only to the sender and receiver. We can't tell whether a message is heading to the origin server or the client, because both are downstream.
즉 - 발신자는 무조건 "upstream"이고 수신자는 무조건 "downstream"임

Figure 3-2. All messages flow downstream
2. The Parts of a Message
HTTP messages are simple, formatted blocks of data. Take a peek at Figure 3-3 for an example. Each message contains either a request form a client or response from a server. They consist of three parts: a start line describing the message, a block of headers containing attributes, and an optional body containing data.

Figure 3-3. Three parts of an HTTP message
The start line and headers are just ASCII text, broken up by lines. Each line ends with a two-character end-of-line sequence, consisting of a carriage return (ASCII 13) and a line-feed character (ASCII 10). This end-of-line sequence is written "CRLF". It is worth pointing out that while the HTTP specification for terminating lines is CRLF, robust applications also should accept just a line-feed character. Some older or broken HTTP applications do not always send both carriage return and line feed.
Carriage Return(CR) - \r
Line-Feed(LF) - \n
The entity body or message body (or just plain "body") is simply an optional chunk of data. Unlike the start line and headers, the body can contain text or binary data or can be empty.
In the example in Figure 3-3, the headers give you a bit of information about the body. The Content-Type line tells you what the body is— in this example, it is a plain-text document. The Content-Length line tells you how big the body is; here it is a meager 19 bytes.
2.1. Message Syntax
All HTTP messages fall into two types: request messages and response messages. Request messages request an action from a web server. Response messages carry results of a request back to client. Both request and response messages have the same basic message structure. Figure 3-4 shows request and response messages to get a GIF image.

Figure 3-4. An HTTP transaction has request and response messages
Here's the format for a request message:
<method> <request-URL> <version>
<headers>
<entity-body>
Here's the format for a response message (note that the syntax differs only in the start line):
<version> <status> <reason-phrase>
<headers>
<entity-body>
Here's a quick description of the various parts:
method
The action that the client wants the server to perform on the resource. It is a single word, like "GET", "HEAD", or "POST". We cover the method in detail later in this chapter.
request-URL
A complete URL naming the requested resource, or the path component of the URL. If you are talking directly to the server, the path component of the URL is usually okay as long as it is the absolute path to the resource — the server can assume ifself as the host/port of the URL. Chapter 2 covers URL syntax in detail.
version
The version of HTTP that the message is using. Its format looks like:
HTTP/<major>.<minor>
where major and minor both are integers. We discuss HTTP versioning a bit more later in this chapter.
status-code
A three-digit number describing what happened during the request. The first digit of each code decribes the general class of status ("success", "error", etc.). An exhaustive list of status codes defined in the HTTP specification and their meanings is provided later in this chapter.
reason-phrase
A human-readable version of the numeric status code, consisting of all the text until the end-of-line sequence. Example reason phrases for all the status codes defined in the HTTP specification are provided later in this chapter. The reason phrase is meant solely for human consumption, so, for example, response lines containing "HTTP/1.0 200 NOT OK" and "HTTP/1.0 200 OK" should be treated as equivalent success indications, despite the reason phrases suggesting otherwise.
headers
Zero or more headers, each of which is a name, followed by a colon (:), followed by optional whitespace, followed by a value, followed by a CRLF. The headers are terminated by a blank line (CRLF), marking the end of the list of headers and the beginning of the entity body. Some versions of HTTP, such as HTTP/1.1, require certain headers to be present for the request or response messages to be valid. The various HTTP headers are covered later in this chapter.
entity-body
The entity body contains a block of artitrary data. Not all messages contain entity bodies, so sometimes a message terminates with a bare CRLF. We discuss entities in detail in Chapter 15.

Figure 3-5. Example request and response messages
Note that a set of HTTP headers should always end in a blank line (bare CRLF), even if there are no headers and even if there is no entity body. Historically, however, many clients and server (mistakenly) omitted the final CRLF if there was no entity body.
2.2. Start Lines
All HTTP messages begin with a start line. The start line for a request messages say what to to. The start line for a response message says what happend.
Request line
Request messages ask servers to do something to a resource. The start line for a request messages, or request line, contains a method describing what operation the server should perform and a reqeuest URL describing the resource on which to perform the method. The request line also includes an HTTP version which tell the server what dialect of HTTP the client is speaking.
All of these fields are separated by whitespace. In Figure 3-5a, the request method is GET, the request URL is /test/hi-there.txt, and the version is HTTP/1.1. Prior to HTTP/1.0, request lines were not required to contain an HTTP version.
Response line
Response messages carry status information and any resulting data from an operation back to a client. The start line for a response message, or response line, contains the HTTP version that the response message is using, a numeric status code, and a textual reason phrase describing the status of the operation.
All these fields are separated by whitespace. In Figure 3-5b, the HTTP version is HTTP/1.0, the status code is 200 (indicating success), and the reason phrase is OK, meaning the document was returned successfully. Prior to HTTP/1.0, responses were not required to contain a response line.
Methods
The method begins the start line of requests, telling the server what to do. For example, in the line “GET /specials/saw-blade.gif HTTP/1.0,” the method is GET.
The HTTP specifications have defined a set of common request methods. For example, the GET method gets a document from a server, the POST method sends data to a server for processing, and the OPTIONS method determines the general capabilites of a web server or the capabilities of a web server for a specific resource.
Table 3-1 describes seven of these methods. Note that some methods have a body in the request message, and other methods have bodyless requests.

Table 3-1. Common HTTP methods
Not all servers implement all seven of the methods in Table 3-1. Furthermore, because HTTP was designed to be easily extensible, other servers may implement their own request methods in addition to these. These additional methods are called extension methods, because they extend the HTTP specification.
Status codes
As methods tell the server what to do, status codes tell the client what happened. Status codes live in the start lines of responses. For example, in the line “HTTP/1.0 200 OK,” the status code is 200.
When clients send request messages to an HTTP server, many things can happen. If you are fortunate, the request will complete successfully. You might not always be so lucky. The server may tell you that the resource you requested could not be found, that you don’t have permission to access the resource, or perhaps that the resource has moved someplace else.
Status codes are returned in the start line of each response message. Both a numeric and a human-readable status are returned. The numeric code makes error processing easy for programs, while the reason phrase is easily understood by humans.
The different status codes are grouped into classes by their three-digit numeric codes. Status codes between 200 and 299 represent success. Codes between 300 and 399 indicate that the resource has been moved. Codes between 400 and 499 mean that the client did something wrong in the request. Codes between 500 and 599 mean something went awry on the server.
The status code classes are shown in Table 3-2.

Table 3-2. Status code classes
Current versions of HTTP define only a few codes for each status category. As the protocol evolves, more status codes will be defined officially in the HTTP specification. If you receive a status code that you don't recognize, chances are someone has defined it as an extension to the current protocol. You should treat it as a general member of the class whose range it falls into.
For example, if you receive status code 515 (which is outside of the defined range for 5XX codes listed in Table 3-2), you should treat the response as indicating a server error, which is the general class of 5XX messages.
Table 3-3 lists some of the most common status codes that you will see. We will explain all the current HTTP status codes in detail later in this chapter.

Table 3-3. Common status codes
Reason phrases
The reason phrase is the last component of the start line of the response. It provides a textual explanation of the status code. For example, in the line “HTTP/1.0 200 OK,” the reason phrase is OK.
Reason phrases are paired one-to-one with status codes. The reason phrase provides a human-readable version of the status code that application developers can pass along to their users to indicate what happened during the request.
The HTTP specification does not provide any hard and fast rules for what reason phrases should look like. Later in this chapter, we list the status codes and some suggested reason phrases.
Version numbers
Version numbers appear in both request and response message start lines in the format HTTP/x.y. They provide a means for HTTP applications to tell each other what version of the protocol they conform to.
Version numbers are intended to provide applications speaking HTTP with a clue about each other’s capabilities and the format of the message. An HTTP Version 1.2 application communicating with an HTTP Version 1.1 application should know that it should not use any new 1.2 features, as they likely are not implemented by the application speaking the older version of the protocol.
The version number indicates the highest version of HTTP that an application supports. In some cases this leads to confusion between applications,* because HTTP/1.0 applications interpret a response with HTTP/1.1 in it to indicate that the response is a 1.1 response, when in fact that’s just the level of protocol used by the responding application.
Note that version numbers are not treated as fractional numbers. Each number in the version (for example, the “1” and “0” in HTTP/1.0) is treated as a separate number. So, when comparing HTTP versions, each number must be compared separately in order to determine which is the higher version. For example, HTTP/2.22 is a higher version than HTTP/2.3, because 22 is a larger number than 3.
2.3 Headers
The previous section focused on the first line of request and response messages (methods, status codes, reason phrases, and version numbers). Following the start line comes a list of zero, one, or many HTTP header fields (see Figure 3-5).
HTTP header fields add additional information to request and response messages. They are basically just lists of name/value pairs. For example, the following header line assigns the value 19 to the Content-Length header field:
Content-length: 19
Header classifications
The HTTP specification defines several header fields. Applications also are free to invent their own home-brewed headers. HTTP headers are classified into:
General headers
Can appear in both request and response messages
Request headers
Provide more information about the request
Response headers
Provide more infomatino about the response
Entity headers
Decribe body size and contents, or the resource itself.
Extenstion headers
New headers that are not defined in the specification.
Each HTTP header has a simple syntax: a name, followed by a colon (:), followed by optional whitespace, followed by the field value, followed by a CRLF. Table 3-4 lists some common header examples.

Table 3-4. Common header examples
Header continuation lines
Long header lines can be made more readable by breaking them into multiple lines, preceding each extra line with at least one space or tab character.
For example:

In this example, the response message contains a Server header whose value is broken into continuation lines. The complete value of the header is “Test Server Version 1.0”.
We’ll briefly describe all the HTTP headers later in this chapter. We also provide a more detailed reference summary of all the headers in Appendix C.
2.4. Entity Bodies
The third part of an HTTP message is the optional entity body. Entity bodies are the payload of HTTP messages. They are the things that HTTP was designed to transport.
HTTP messages can carry many kinds of digital data: images, video, HTML docu-ments, software applications, credit card transactions, electronic mail, and so on.
2.5. Version 0.9 Messages
Skip
3. Methods
Let’s talk in more detail about some of the basic HTTP methods, listed earlier in Table 3-1. Note that not all methods are implemented by every server. To be com-pliant with HTTP Version 1.1, a server need implement only the GET and HEAD methods for its resources.
Even when servers do implement all of these methods, the methods most likely have restricted uses. For example, servers that support DELETE or PUT (described later in this section) would not want just anyone to be able to delete or store resources. These restrictions generally are set up in the server’s configuration, so they vary from site to site and from server to server.
3.1. Safe Methods
HTTP defines a set of methods that are called safe methods. The GET and HEAD methods are said to be safe, meaning that no action should occur as a result of an HTTP request that uses either the GET or HEAD method.
By no action, we mean that nothing will happen on the server as a result of the HTTP request. For example, consider when you are shopping online at Joe’s Hard- ware and you click on the “submit purchase” button. Clicking on the button sub- mits a POST request (discussed later) with your credit card information, and an action is performed on the server on your behalf. In this case, the action is your credit card being charged for your purchase.
There is no guarantee that a safe method won’t cause an action to be performed (in practice, that is up to the web developers). Safe methods are meant to allow HTTP application developers to let users know when an unsafe method that may cause some action to be performed is being used. In our Joe’s Hardware example, your web browser may pop up a warning message letting you know that you are making a request with an unsafe method and that, as a result, something might happen on the server (e.g., your credit card being charged).
3.2. GET
GET is the most common method. It usually is used to ask a server to send a resource. HTTP/1.1 requires servers to implement this method. Figure 3-7 shows an example of a client making an HTTP request with the GET method.
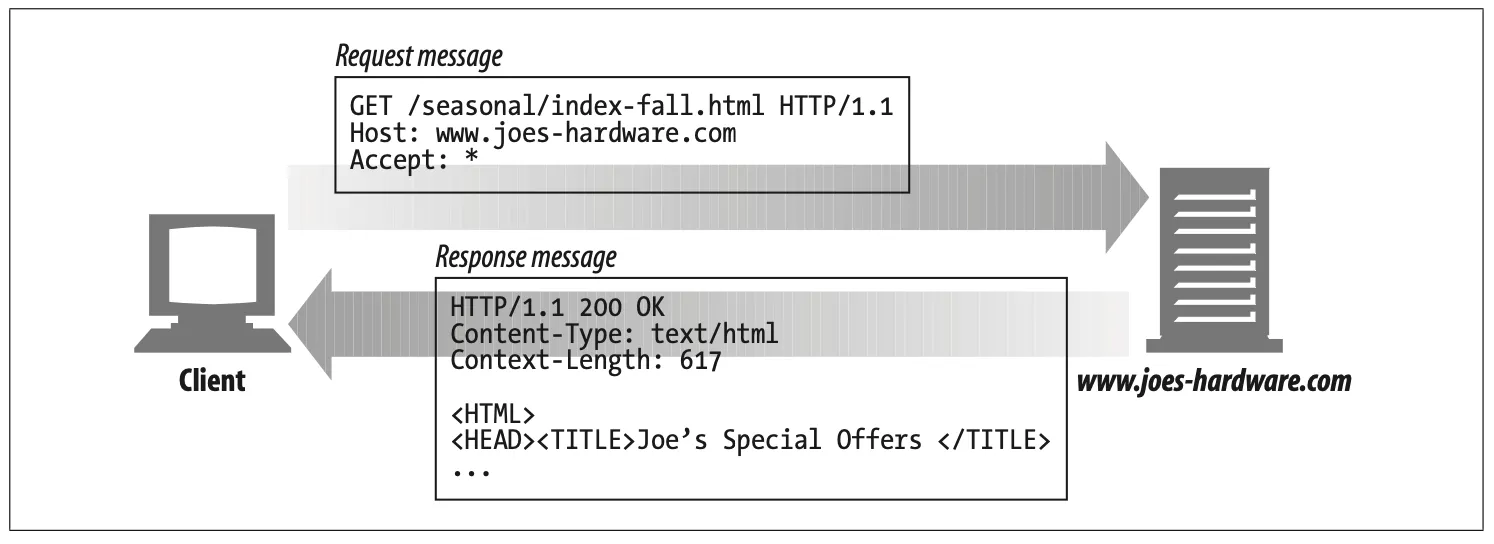
Figure 3-7. GET example
3.3. HEAD
The HEAD method behaves exactly like the GET method, but the server returns only the headers in the response. No entity body is ever returned. This allows a client to inspect the headers for a resource without having to actually get the resource. Using HEAD, you can:
•
Find out about a resource (e.g., determine its type) without getting it.
•
See if an object exists, by looking at the status code of the response.
•
Test if the resource has been modified, by looking at the headers.
Server developers must ensure that the headers returned are exactly those that a GET request would return. The HEAD method also is required for HTTP/1.1 compli- ance. Figure 3-8 shows the HEAD method in action.

Figure 3-8. HEAD example
3.4. PUT
The PUT method writes documents to a server, in the inverse of the way that GET reads documents from a server. Some publishing systems let you create web pages and install them directly on a web server using PUT (see Figure 3-9).

Figure 3-9. PUT example
The semantics of the PUT method are for the server to take the body of the request and either use it to create a new document named by the requested URL or, if that URL already exists, use the body to replace it.
Because PUT allows you to change content, many web servers require you to log in with a password before you can perform a PUT. You can read more about password authentication in Chapter 12.
3.5. POST
The POST method was designed to send input data to the server.* In practice, it is often used to support HTML forms. The data from a filled-in form typically is sent to the server, which then marshals it off to where it needs to go (e.g., to a server gateway program, which then processes it). Figure 3-10 shows a client making an HTTP request—sending form data to a server—with the POST method.

Figure 3-10. POST example
POST is used to send data to a server. PUT is used to deposit data into a resource on the server (e.g., a file).
3.6. TRACE
When a client makes a request, that request may have to travel through firewalls, proxies, gateways, or other applications. Each of these has the opportunity to modify the original HTTP request. The TRACE method allows clients to see how its request looks when it finally makes it to the server.
A TRACE request initiates a "loopback" diagnostic at the destination server. The server at the final leg of the trip bounces back a TRACE response, with the virgin request message it received in the body of its response. A client can then see how, or if, its original message was mugned or modified along the request/reponse chain of any intervening HTTP applications (see Figure 3-11).
The TRACE method is used primarily for diagnostics; i.e., verifying that requests are going through the request/response chain as intended. It’s also a good tool for seeing the effects of proxies and other applications on your requests.
As good as TRACE is for diagnostics, it does have the drawback of assuming that intervening applications will treat different types of requests (different methods—GET, HEAD, POST, etc.) the same. Many HTTP applications do different things depending on the method—for example, a proxy might pass a POST request directly to the server but attempt to send a GET request to another HTTP application (such as a web cache). TRACE does not provide a mechanism to distinguish methods. Generally, intervening applications make the call as to how they process a TRACE request.
No entity body can be sent with a TRACE request. The entity body of the TRACE response contains, verbatim, the request that the responding server received.
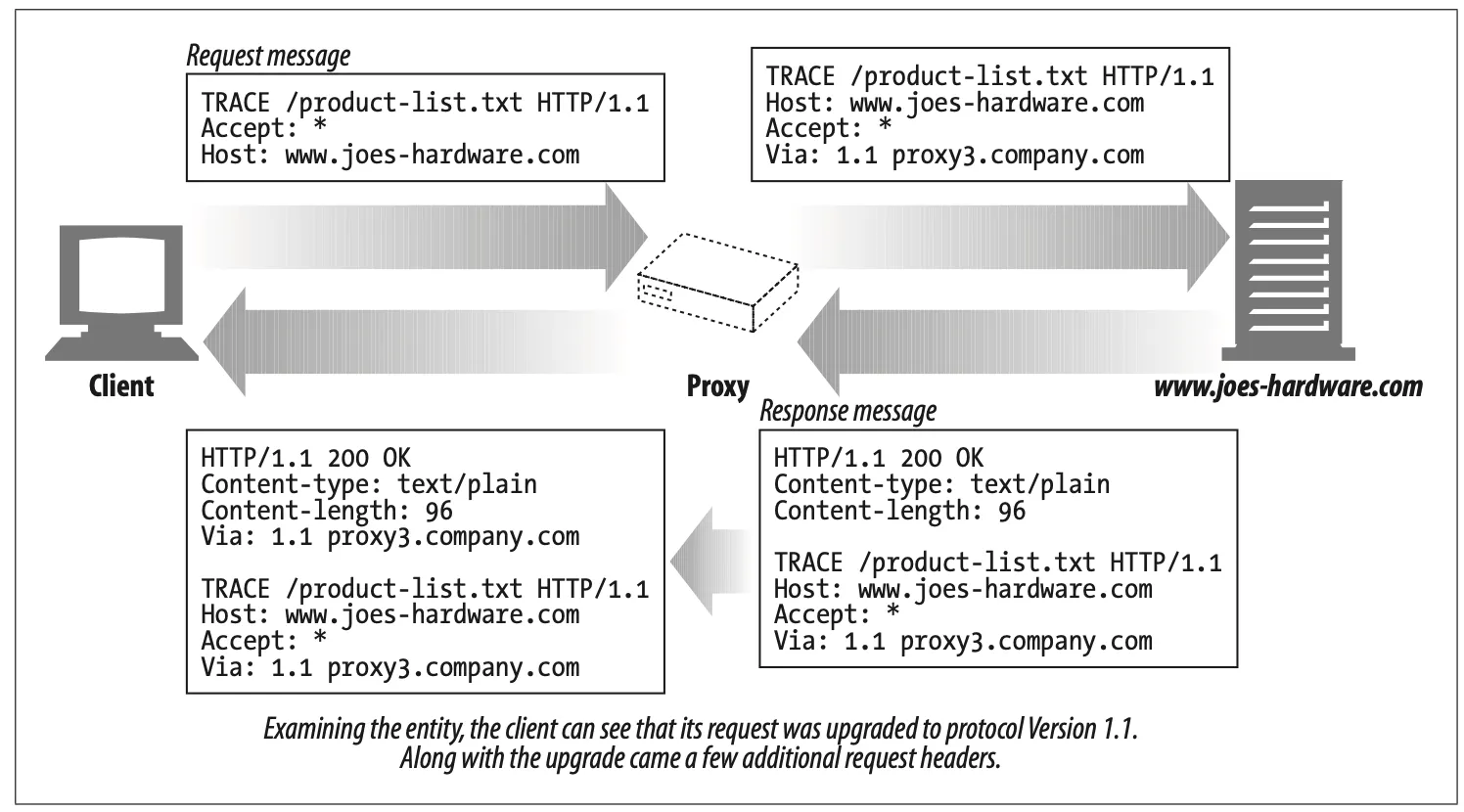
Figure 3-11. TRACE example
3.7. OPTIONS
The OPTIONS method asks the server to tell us about the various supported capabilities of the web server. You can ask a server about what methods it supports in general or for particular resources. (Some servers may support particular operations only on particular kinds of objects).
This provides a means for client applications to determine how best to access various resources with out actually having to access them. Figure 3-12 shows a request scenario using the OPTIONS method.
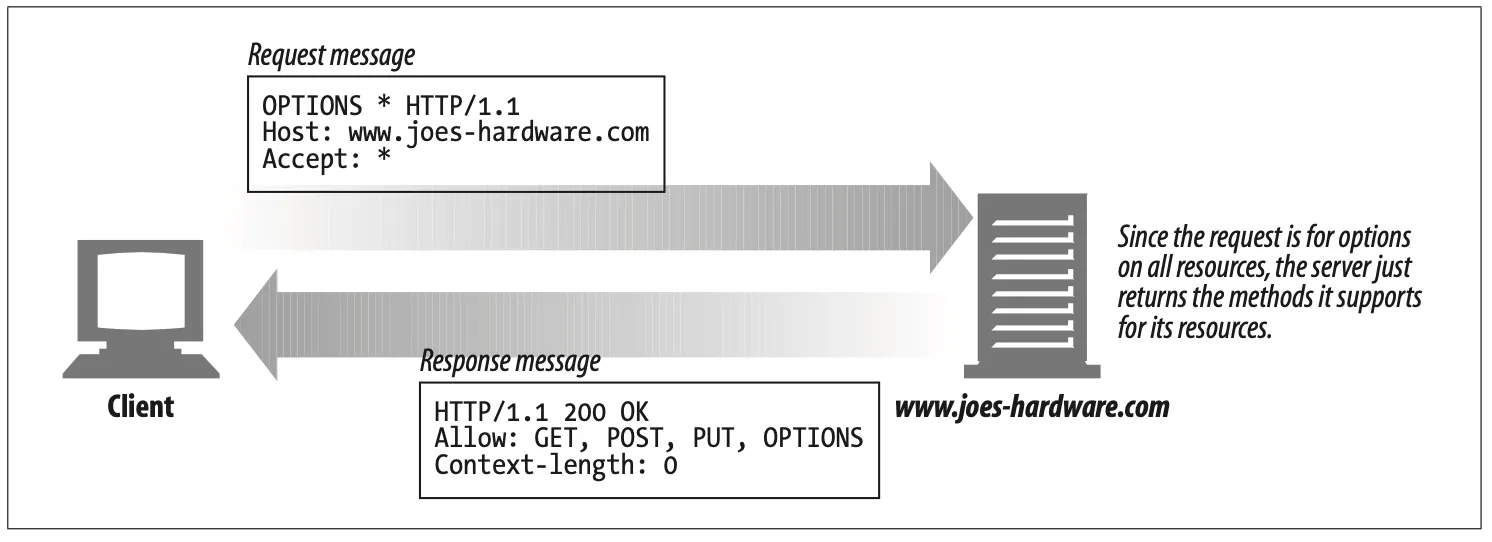
Figure 3-12. OPTIONS example
3.8. DELETE
The DELETE method does just what you would think—it asks the server to delete the resources specified by the request URL. However, the client application is not guaranteed that the delete is carried out. This is because the HTTP specification allows the server to override the request without telling the client. Figure 3-13 shows an example of the DELETE method.

Figure 3-13. DELETE example
3.9. Extension Methods
HTTP was designed to be field-extensible, so new features wouldn’t cause older software to fail. Extension methods are methods that are not defined in the HTTP/1.1 specification. They provide developers with a means of extending the capabilities of the HTTP services their servers implement on the resources that the servers manage. Some common examples of extension methods are listed in Table 3-5. These methods are all part of the WebDAV HTTP extension (see Chapter 19) that helps support publishing of web content to web servers over HTTP.

Table 3-5. Example web publishing extension methods
It’s important to note that not all extension methods are defined in a formal specifi- cation. If you define an extension method, it’s likely not to be understood by most HTTP applications. Likewise, it’s possible that your HTTP applications could run into extension methods being used by other applications that it does not understand.
In these cases, it is best to be tolerant of extension methods. Proxies should try to relay messages with unknown methods through to downstream servers if they are capable of doing that without breaking end-to-end behavior. Otherwise, they should respond with a 501 Not Implemented status code. Dealing with extension methods (and HTTP extensions in general) is best done with the old rule, “be conservative in what you send, be liberal in what you accept.”
4. Status Codes
HTTP status codes are classified into five broad categories, as shown earlier in Table 3-2. This section summarizes the HTTP status codes for each of the five classes.
The status codes provide an easy way for clients to understand the results of their transactions. In this section, we also list example reason phrases, though there is no real guidance on the exact text for reason phrases. We include the recommen-ded reason phrases from the HTTP/1.1 specification.
4.1. 100-199: Informational Status Codes
HTTP/1.1 introduced the informational status codes to the protocol. They are relat-ively new and subject to a bit of controversy about their complexity and perceived value. Table 3-6 lists the defined informational status codes.

Table 3-6. Informational status codes and reason phrases
The 100 Continue status code, in particular, is a bit confusing. It’s intended to opti- mize the case where an HTTP client application has an entity body to send to a server but wants to check that the server will accept the entity before it sends it. We discuss it here in a bit more detail (how it interacts with clients, servers, and proxies) because it tends to confuse HTTP programmers.
Clients and 100 Continue
If a client is sending an entity to a server and is willing to wait for a 100 Continue response before it sends the entity, the client needs to send an Expect request header (see Appendix C) with the value 100-continue. If the client is not sending an entity, it shouldn’t send a 100-continue Expect header, because this will only confuse the server into thinking that the client might be sending an entity.
100-continue, in many ways, is an optimization. A client application should really use 100-continue only to avoid sending a server a large entity that the server will not be able to handle or use.
Because of the initial confusion around the 100 Continue status (and given some of the older implementations out there), clients that send an Expect header for 100-continue should not wait forever for the server to send a 100 Continue response. After some timeout, the client should just send the entity.
In practice, client implementors also should be prepared to deal with unexpected 100 Continue responses (annoying, but true). Some errant HTTP applications send this code inappropriately.
Servers and 100 Continue
If a server receives a request with the Expect header and 100-continue value, it should respond with either the 100 Continue response or an error code (see Table 3-9). Servers should never send a 100 Continue status code to clients that do not send the 100-continue expectation. However, as we noted above, some errant servers do this.
If for some reason the server receives some (or all) of the entity before it has had a chance to send a 100 Continue response, it does not need to send this status code, because the client already has decided to continue. When the server is done reading the request, however, it still needs to send a final status code for the request (it can just skip the 100 Continue status).
Finally, if a server receives a request with a 100-continue expectation and it decides to end the request before it has read the entity body (e.g., because an error has occurred), it should not just send a response and close the connection, as this can prevent the client from receiving the response (see “TCP close and reset errors” in Chapter 4).
Proxies and 100 Continue
A proxy that receives from a client a request that contains the 100-continue expectation needs to do a few things. If the proxy either knows that the next-hop server (dis- cussed in Chapter 6) is HTTP/1.1-compliant or does not know what version the next-hop server is compliant with, it should forward the request with the Expect header in it. If it knows that the next-hop server is compliant with a version of HTTP earlier than 1.1, it should respond with the 417 Expectation Failed error.
If a proxy decides to include an Expect header and 100-continue value in its request on behalf of a client that is compliant with HTTP/1.0 or earlier, it should not forward the 100 Continue response (if it receives one from the server) to the client, because the client won’t know what to make of it.
It can pay for proxies to maintain some state about next-hop servers and the ver- sions of HTTP they support (at least for servers that have received recent requests), so they can better handle requests received with a 100-continue expectation.
4.2. 200-299: Success Status Codes
When clients make requests, the requests usually are successful. Servers have an array of status codes to indicate success, matched up with different types of requests. Table 3-7 lists the defined success status codes.
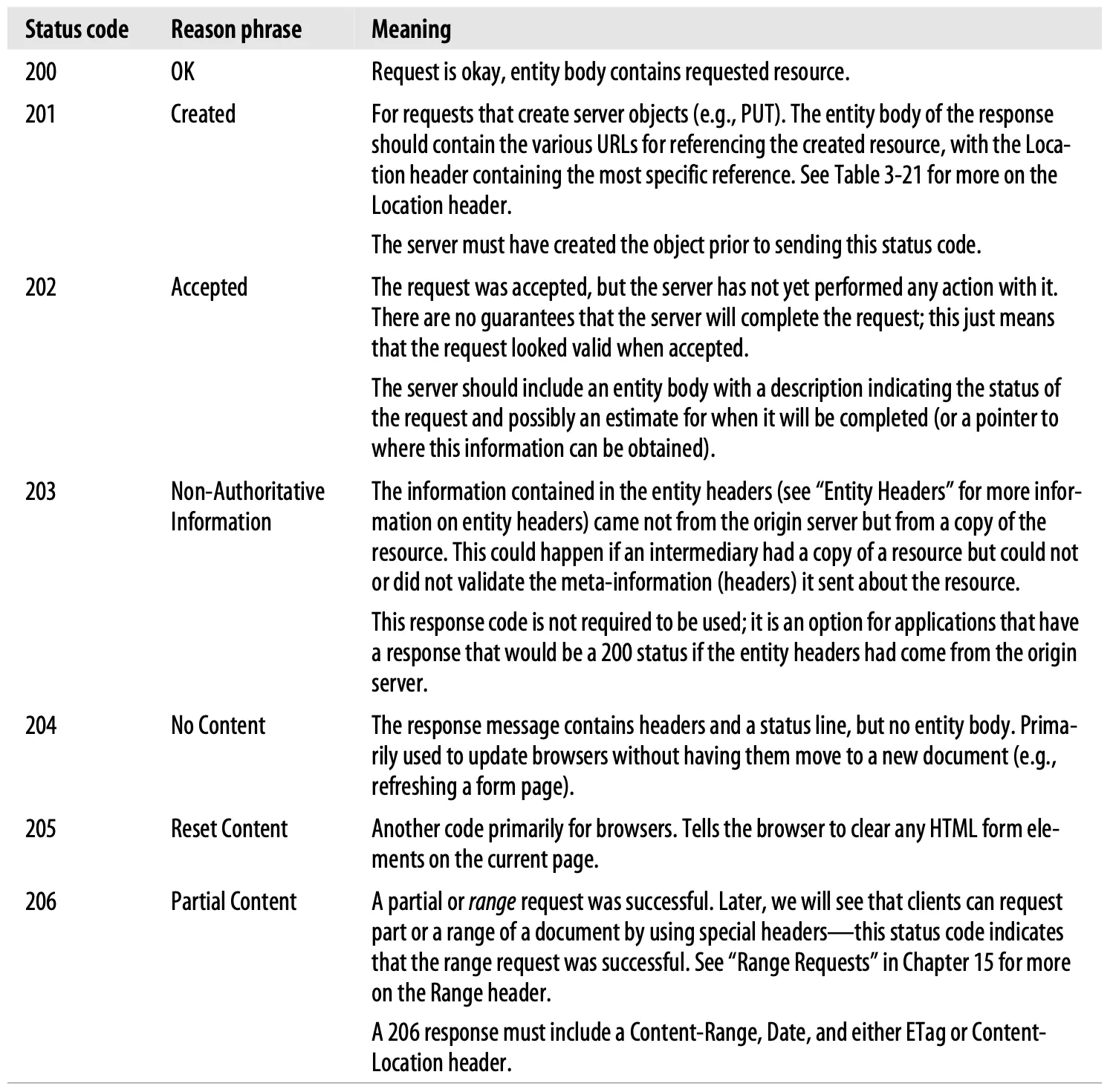
Table 3-7. Success status codes and reason phrases
4.3. 300-399: Redirection Status Codes
The redirection status codes either tell clients to use alternate locations for the resources they’re interested in or provide an alternate response instead of the content. If a resource has moved, a redirection status code and an optional Location header can be sent to tell the client that the resource has moved and where it can now be found (see Figure 3-14). This allows browsers to go to the new location transparently, without bothering their human users.

Figure 3-14. Redirected request to new location
Some of the redirection status codes can be used to validate an application’s local copy of a resource with the origin server. For example, an HTTP application can check if the local copy of its resource is still up-to-date or if the resource has been modified on the origin server. Figure 3-15 shows an example of this. The client sends a special If-Modified-Since header saying to get the document only if it has been modified since October 1997. The document has not changed since this date, so the server replies with a 304 status code instead of the contents.
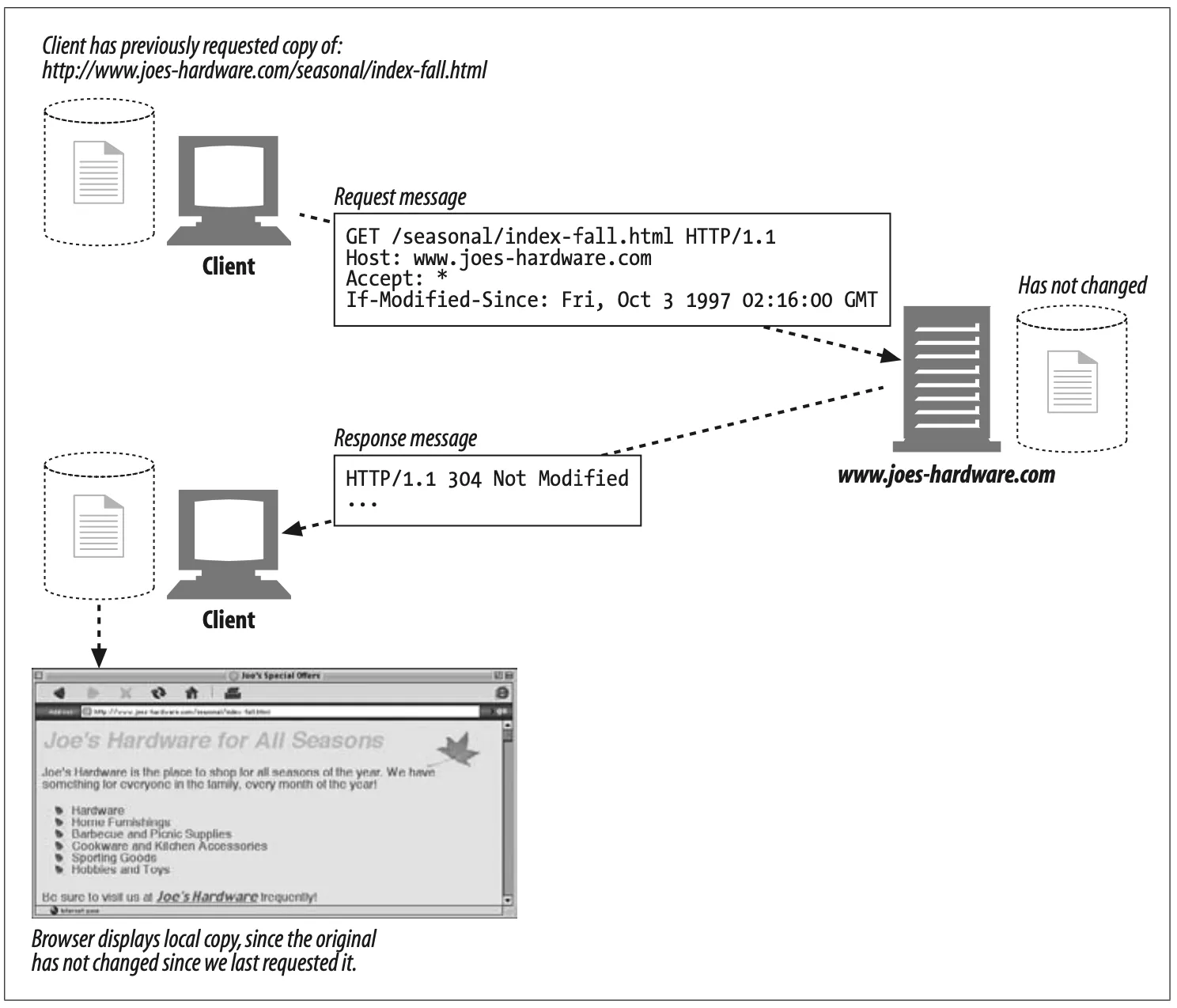
Figure 3-15. Request redirected to use local copy
In general, it’s good practice for responses to non-HEAD requests that include a redirection status code to include an entity with a description and links to the redirected URL(s)—see the first response message in Figure 3-14. Table 3-8 lists the defined redirection status codes.


Table 3-8. Redirection status codes and reason phrases
From Table 3-8, you may have noticed a bit of overlap between the 302, 303, and 307 status codes. There is some nuance to how these status codes are used, most of which stems from differences in the ways that HTTP/1.0 and HTTP/1.1 applications treat these status codes.
When an HTTP/1.0 client makes a POST request and receives a 302 redirect status code in response, it will follow the redirect URL in the Location header with a GET request to that URL (instead of making a POST request, as it did in the original request).
HTTP/1.0 servers expect HTTP/1.0 clients to do this—when an HTTP/1.0 server sends a 302 status code after receiving a POST request from an HTTP/1.0 client, the server expects that client to follow the redirect with a GET request to the redirected URL.
The confusion comes in with HTTP/1.1. The HTTP/1.1 specification uses the 303 status code to get this same behavior (servers send the 303 status code to redirect a client’s POST request to be followed with a GET request).
To get around the confusion, the HTTP/1.1 specification says to use the 307 status code inplace of the 302 status code for temporary redirects to HTTP/1.1 clients. Servers can then save the 302 status code for use with HTTP/1.0 clients.
What this all boils down to is that servers need to check a client’s HTTP version to properly select which redirect status code to send in a redirect response.
어렵다... 이 부분 다시 한번 봐야할듯...
4.4. 400-499: Client Error Status Codes
Sometimes a client sends something that a server just can’t handle, such as a badly formed request message or, most often, a request for a URL that does not exist.
We’ve all seen the infamous 404 Not Found error code while browsing—this is just the server telling us that we have requested a resource about which it knows nothing.
Many of the client errors are dealt with by your browser, without it ever bothering you. A few, like 404, might still pass through. Table 3-9 shows the various client error status codes.


Table 3-9. Client error status codes and reason phrases
4.5. 500-599: Server Error Status Codes
Sometimes a client sends a valid request, but the server itself has an error. This could be a client running into a limitation of the server or an error in one of the server’s subcomponents, such as a gateway resource.
Proxies often run into problems when trying to talk to servers on a client’s behalf. Proxies issue 5XX server error status codes to describe the problem (Chapter 6 covers this in detail). Table 3-10 lists the defined server error status codes.


Table 3-10. Server error status codes and reason phrases
5. Headers
Headers and methods work together to determine what clients and servers do. This section quickly sketches the purposes of the standard HTTP headers and some headers that are not explicitly defined in the HTTP/1.1 specification (RFC 2616). Appendix C summarizes all these headers in more detail.
There are headers that are specific for each type of message and headers that are more general in purpose, providing information in both request and response mes- sages. Headers fall into five main classes:
General headers
These are generic headers used by both clients and servers. They serve general purposes that are useful for clients, servers, and other applications to supply to one another. For example, the Date header is a general-purpose header that allows both sides to indicate the time and date at which the message was constructed:
Date: Tue, 3 Oct 1974 02:16:00 GMT
Request headers
As the name implies, request headers are specific to request messages. They provide extra information to servers, such as what type of data the client is willing to receive. For example, the following Accept header tells the server that the client will accept any media type that matches its request:
Accept: /
Response headers
Response messages have their own set of headers that provide information to the client (e.g., what type of server the client is talking to). For example, the following Server header tells the client that it is talking to a Version 1.0 Tiki-Hut server:
Server: Tiki-Hut/1.0
Entity headers
Entity headers refer to headers that deal with the entity body. For instance, entity headers can tell the type of the data in the entity body. For example, the following Content-Type header lets the application know that the data is an HTML document in the iso-latin-1 character set:
Content-Type: text/html; charset=iso-latin-1
Extension headers
Extension headers are nonstandard headers that have been created by application developers but not yet added to the sanctioned HTTP specification. HTTP programs need to tolerate and forward extension headers, even if they don’t know what the headers mean.
5.1. General Headers
Some headers provide very basic information about a message. These headers are called general headers. They are the fence straddlers, supplying useful information about a message regardless of its type.
For example, whether you are constructing a request message or a response mes- sage, the date and time the message is created means the same thing, so the header that provides this kind of information is general to both types of messages.

Table 3-11. General informational headers
General caching headers
HTTP/1.0 introduced the first headers that allowed HTTP applications to cache local copies of objects instead of always fetching them directly from the origin server. The latest version of HTTP has a very rich set of cache parameters. In Chapter 7, we cover caching in depth. Table 3-12 lists the basic caching headers.

Table 3-12. General caching headers
5.2. Request Headers
Request headers are headers that make sense only in a request message. They give information about who or what is sending the request, where the request originated, or what the preferences and capabilities of the client are. Servers can use the information the request headers give them about the client to try to give the client a better response. Table 3-13 lists the request informational headers.

Table 3-13. Request informational headers
Accept headers
Accept headers give the client a way to tell servers their preferences and capabilities: what they want, what they can use, and, most importantly, what they don’t want. Servers can then use this extra information to make more intelligent decisions about what to send. Accept headers benefit both sides of the connection. Clients get what they want, and servers don’t waste their time and bandwidth sending something the client can’t use. Table 3-14 lists the various accept headers.

Table 3-14. Accept headers
Conditional request headers
Sometimes, clients want to put some restrictions on a request. For instance, if the client already has a copy of a document, it might want to ask a server to send the document only if it is different from the copy the client already has. Using conditional request headers, clients can put such restrictions on requests, requiring the server to make sure that the conditions are true before satisfying the request. Table 3-15 lists the various conditional request headers.

Table 3-15. Conditional request headers
Request security headers
HTTP natively supports a simple challenge/response authentication scheme for requests. It attempts to make transactions slightly more secure by requiring clients to authenticate themselves before getting access to certain resources. We discuss this challenge/response scheme in Chapter 14, along with other security schemes that have been implemented on top of HTTP. Table 3-16 lists the request security headers.

Table 3-16. Request security headers
Proxy request headers
As proxies become increasingly common on the Internet, a few headers have been defined to help them function better. In Chapter 6, we discuss these headers in detail. Table 3-17 lists the proxy request headers.

Table 3-17. Proxy request headers
5.3. Response Headers
Response messages have their own set of response headers. Response headers provide clients with extra information, such as who is sending the response, the capabilities of the responder, or even special instructions regarding the response. These headers help the client deal with the response and make better requests in the future. Table 3-18 lists the response informational headers.

Table 3-18. Response informational headers
Negotiation headers
HTTP/1.1 provides servers and clients with the ability to negotiate for a resource if multiple representations are available—for instance, when there are both French and German translations of an HTML document on a server. Chapter 17 walks through negotiation in detail. Here are a few headers servers use to convey information about resources that are negotiable. Table 3-19 lists the negotiation headers.

Table 3-19. Negotiation headers
Response security headers
You’ve already seen the response security headers, which are basically the response side of HTTP’s challenge/response authentication scheme. We talk about security in detail in Chapter 14. For now, here are the basic challenge headers. Table 3-20 lists the response security headers.

Table 3-20. Response security headers
5.4. Entity Headers
There are many headers to describe the payload of HTTP messages. Because both request and response messages can contain entities, these headers can appear in either type of message.
Entity headers provide a broad range of information about the entity and its content, from information about the type of the object to valid request methods that can be made on the resource. In general, entity headers tell the receiver of the message what it’s dealing with. Table 3-21 lists the entity informational headers.

Table 3-21. Entity information headers
Content headers
The content headers provide specific information about the content of the entity, revealing its type, size, and other information useful for processing it. For instance, a web browser can look at the content type returned and know how to display the object. Table 3-22 lists the various content headers.


Table 3-22. Content headers
Entity caching headers
The general caching headers provide directives about how or when to cache. The entity caching headers provide information about the entity being cached—for example, information needed to validate whether a cached copy of the resource is still valid and hints about how better to estimate when a cached resource may no longer be valid.
In Chapter 7, we dive deep into the heart of caching HTTP requests and responses. We will see these headers again there. Table 3-23 lists the entity caching headers.

Table 3-23. Entity caching headers
