


RDBMS VERSION
RDBMS | VERSION | VERSION CHECK SQL |
TIBERO | 7 FS02 (Compiled at Jun 20 2022 11:29:40 build seq 202489 init rev {2022-03-10}) | SELECT * FROM VT_VERSION; |
ORACLE | Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production | SELECT * FROM V$VERSION; |
MySQL | 8.0.29 | SELECT VERSION(); |
MariaDB | 10.8.3-MariaDB-1:10.8.3+maria~jammy | SELECT VERSION(); |
MS SQL Server | Microsoft SQL Server 2022 (CTP2.0) - 16.0.600.9 (X64) | SELECT @@VERSION; |
IBM Db2 | DB2 v11.5.7.0 | SELECT * FROM SYSIBMADM.ENV_INST_INFO; |
PostgreSQL | PostgreSQL 14.3 (Debian 14.3-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit | SELECT VERSION(); |
CUBRID | 11.2.0.0658 | SELECT VERSION(); |
NULL
•
NULL의 추상적인 의미
◦
미지의 값
◦
알 수 없는 값
◦
정해지지 않은 값
•
NULL ⇒ 스폐셜 마커
NULL 저장
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
'NULL' | string | string | string | string | string | string | string | string | string |
' ' | string | string | string | string | string | string | string | string | string |
'' | NULL | NULL | string | string | string | string | string | string | string |
•
'' ⇒ empty 값에 NULL 또는 string으로 RDBMS 마다 다른 경우가 있음

이기종 RDBMS간에 데이터 마이그레이션 작업 수행 시 주의
ORACLE (NULL) ⇒ PostgreSQL(NULL) : 문제 없음
PostgreSQL('') ⇒ ORACLE(NULL) : '' 값이 NULL로 치환 되어 결과가 달라지는 문제가 발생할 수 있음 // '' 값을 입력 시 ORACLE NOT NULL 제약 조건에 의해 입력 실패 할 수 있음 (사전 협의 필요)
NULL 저장 SQL
NULL 크기
•
정해지지 않은 값이라고 하지만 데이터 베이스에 정해지지 않은 값이라고 마킹 정도는 해주어야하기 때문에 분명 NULL도 정해진 크기가 있음
TIBERO
ORACLE
TIBERO | ORACLE
MySQL / MariaDB
PostgreSQL
MS SQL Server
CUBRID
IBM Db2
RDBMS별 NULL이 HEAP에 저장되는 실제 크기
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | CUBRID |
NULL 크기 (byte) | 0 | 0 또는 1 | 0 | 0 | 0 | 0 | - | 0 또는 선언된 데이터 타입을 따름 |
NULL 처리 방식
SELECT NULL
SELECT 절 NULL 연산
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
1 + NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
1 - NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
1 * NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
1 / NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
SELECT 절 NULL 문자 결합
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
'A'||NULL||'C’ | AC | AC | NULL (연산) | NULL (연산) | - | NULL | NULL | NULL | NULL |
'A'+NULL+'C’ | - | NULL (연산) | NULL (연산) | NULL (연산) | NULL | - | - | NULL (연산) | NULL |
CONCAT('A',NULL,'C') | - | - | NULL | NULL | AC | AC | - | - | NULL |
CONCAT('A',NULL) | A | A | NULL | NULL | A | A | NULL | - | NULL |
•
NULL (연산) : 문자 결합이 아닌 문자 연산
•
- : 미지원
SELECT 절 NULL 날짜시간 연산
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
날짜시간함수 + NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
SELECT 절 NULL 부울 비교
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
NULL or TRUE | - | - | TRUE (1) | TRUE (1) | - | TRUE | TRUE | TRUE (1) | - |
NULL or FALSE | - | - | NULL | NULL | - | NULL | NULL | NULL | - |
•
TRUE : TRUE 반환
•
TRUE (1) : 1 반환
•
- : 미지원
SELECT 절 NULL처리 SQL
집계 함수
•
테스트 결과를 통해 NULL과의 연산/ 비교는 NULL처리가 되거나 NULL을 무시해버립니다.
•
집계 관련 함수에서는 NULL이 포함된 로우로 인한 어떤 영향이 있을까요
테스트 테이블
x | xx |
1 | NULL |
2 | NULL |
3 | NULL |
4 | 40 |
5 | 50 |
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
COUNT(*) | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
COUNT(x) | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
COUNT(xx) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
SUM(x) | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 |
SUM(xx) | 90 | 90 | 90 | 90 | 90 | 90 | 90 | 90 | 90 |
SUM(x+xx) | 99 | 99 | 99 | 99 | 99 | 99 | 99 | 99 | 99 |
AVG(x) | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
AVG(xx) | 45 | 45 | 45 | 45 | 45 | 45 | 45 | 45 | 45 |
AVG(x+xx) | 49.5 | 49.5 | 49.5 | 49.5 | 49 | 49.5 | 49 | 49.5 | 49.5 |
•
집계 함수에서는 NULL 로우는 포함하지 않고 집계가 수행 됩니다.
◦
COUNT(xx), SUM(xx), AVG(xx)
•
집계 함수에서 두개 이상의 COLUMN을 같이할 경우 NULL 로우에 해당하는 값은 전부 무시 됩니다.
◦
x 컬럼과 xx컬럼의 NULL 값을 고려하지 않고 집계 함수가 사용 될 경우 의도한 결과가 도출 되지 않을 수 있습니다.
◦
SUM(x+xx), AVG(x+xx)
•
비교 대상 RDBMS 모두 동일 합니다. 다만, 소수점 처리에서 차이가 있습니다.
◦
소수점자리를 버리는 경우가 있음.
▪
MS SQL, IBM Db2 : 정수를 연산했을 때 소수점이 나오면 버리는 특성
주의 사항
•
데이터베이스에 지원하지 않는 함수가 없는 경우 PROCEDURE를 생성하여 사용 할 때 주의
외부 함수/프로시저 작성 시 주의 SQL
집계 함수 NULL처리 SQL
NULL 정렬
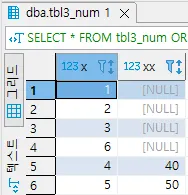
숫자형
x | xx |
1 | NULL |
2 | NULL |
3 | NULL |
4 | 40 |
5 | 50 |
6 | NULL |
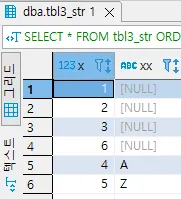
문자형
x | xx |
1 | NULL |
2 | NULL |
3 | NULL |
4 | A |
5 | Z |
6 | NULL |
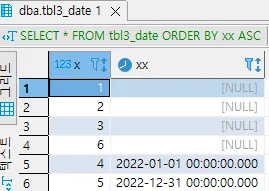
날짜형
x | xx |
1 | NULL |
2 | NULL |
3 | NULL |
4 | 2022-01-01 00:00:00.000 |
5 | 2022-12-31 00:00:00.000 |
6 | NULL |
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | SQLite | CUBRID |
NUMBER ORDER BY xx ASC; | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 | 가장 작은 값 | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 |
STRING ORDER BY xx ASC; | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 | 가장 작은 값 | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 |
DATETIME ORDER BY xx ASC; | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 | 가장 작은 값 | 가장 큰 값 | 가장 큰 값 | 가장 작은 값 | 가장 작은 값 |
가장 작은 값
가장 큰 값
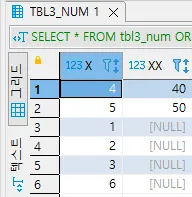
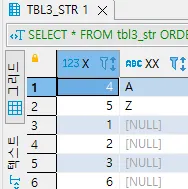
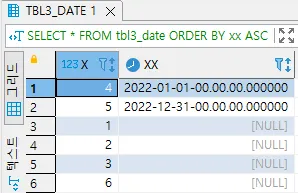
•
ORDER BY 를 수행하여 정렬을 수행하면 분명 NULL의 크고 작음을 확인 할 수 있습니다.
•
MIN/MAX 집계 함수 결과에서는 NULL을 값으로 처리하지 않음
RDBMS | ORACLE, TIBERO, MySQL, MariaDB, MS SQL Server, PostgreSQL, IBM Db2, SQLite, CUBRID |
NUMBER MIN(x),MIN(xx) | 1 40 |
NUMBER MAX(x),MAX(xx) | 6 50 |
STRING MIN(x),MIN(xx) | 1 A |
STRING MAX(x),MAX(xx) | 6 Z |
DATETIME MIN(x),MIN(xx) | 1 2022-01-01-00.00.00.000000 |
DATETIME MAX(x),MAX(xx) | 6 2022-12-31-00.00.00.000000 |
NULL SORT SQL
NULL INDEX
INDEX와 NULL
1번 SQL : SELECT * FROM tbl WHERE xx IS NOT NULL;
2번 SQL : SELECT * FROM tbl WHERE xx IS NULL;
CREATE INDEX idx_tbl_x ON tbl(xx);
SQL
복사
•
INDEX에 NULL 포함
◦
1번 SQL : NULL이 아닌 것만 INDEX FFS SCAN 수행
◦
2번 SQL : NULL인 것을 찾기 위해 INDEX RANGE SCAN 수행
•
INDEX에 NULL 미포함
◦
1번 SQL : NULL이 아닌 것만 INDEX FFS SCAN 수행
◦
2번 SQL : NULL인 것을 찾기 위해 TABLE ACCESS (FULL) 수행
데이터 건수(NOT NULL: 60,000 / NULL: 4,000)
TOTAL_CNT | NOTNULL_CNT | NULL_CNT |
64,000 | 60,000 | 4,000 |
데이터 분포도
X | XX | COUNT(*) |
1 | NULL | 1,000 |
2 | 20 | 10,000 |
3 | NULL | 1,000 |
4 | 40 | 10,000 |
5 | NULL | 1,000 |
6 | 60 | 10,000 |
7 | 70 | 10,000 |
8 | NULL | 1,000 |
9 | 90 | 10,000 |
10 | 100 | 10,000 |
TIBERO
ORACLE
MySQL / MariaDB
PostgreSQL
MS SQL Server
IBM Db2
CUBRID
RDBMS별 INDEX에 NULL 포함 여부 확인
RDBMS | ORACLE | TIBERO | MySQL | MariaDB | MS SQL Server | PostgreSQL | IBM Db2 | CUBRID |
INDEX NULL 포함 여부 (단일) | X (단일) | X (단일) | O (단일,복합) | O (단일,복합) | O (단일,복합) | O (단일,복합) | O (단일,복합) | X (단일) |
RDBMS | ORACLE | TIBERO | CUBRID |
단일 컬럼 | X | X | X |
복합 컬럼
특정 컬럼의 NOT NULL일 경우 | O | O | X |
복합키 NULL 인덱스 구성 검증 SQL
•
IS NULL
◦
INDEX에 NULL 포함 RDBMS
▪
INDEX 스캔을 통해 NULL의 결과 확인
◦
INDEX에 NULL 미포함 RDBMS
▪
함수 기반 인덱스 활용 : NVL(xx, ‘unkown’) 형태로 만들어서 활용
▪
ORACLE, TIBERO의 경우 복합 인덱스 컬럼에 포함 된 컬럼이 1개 이상 NOT NULL 제약 조건에 해당하면 다른 컬럼은 NULL을 포함한다.
•
([notnull column], xx)
▪
ORACLE, TIBERO의 경우 복합 인덱스 구성 시 NOT NULL 제약 조건 컬럼이 없을 경우 NULL을 인덱스에 포함하고 싶을 경우
•
(xx,’1’)
•
IS NOT NULL
◦
INDEX에 NULL 포함 RDBMS
▪
INDEX 스캔을 통해 NULL이 아닌 결과 확인
◦
INDEX에 NULL 미포함 RDBMS
▪
해당 컬럼의 MIN 값을 구해서 활용
•
공백을 string으로 처리하는 RDBMS의 경우
◦
정수 또는 문자: WHERE xx >=’’; 활용
◦
음수 : WHERE xx > (select MIN(xx)-99 from tbl9_null limit1);
•
ORACLE, TIBERO는 INDEX FFS 자동으로 동작
▪
ORACLE, TIBERO의 경우 복합 인덱스 컬럼에 포함 된 컬럼이 1개 이상 NOT NULL 제약 조건에 해당하면 다른 컬럼은 NULL을 포함한다.
•
([notnull column], xx)
▪
ORACLE, TIBERO의 경우 복합 인덱스 구성 시 NOT NULL 제약 조건 컬럼이 없을 경우 NULL을 인덱스에 포함하고 싶을 경우
•
(xx,’1’)
정리
NULL 저장
•
'' (empty) 값이 RDBMS(이하: DB) 마다 NULL 또는 문자열 취급이 다르다.
•
문자열 취급 DB에서 NULL 처리 DB로 이관 시 주의 필요 (결과 값이 달라질 수 있으면 제약 조건 위반이 되어 이관 자체 건수에서 배제 될 수 있다.)
NULL 크기
•
DB마다 NULL 크기 3개 패턴이 있다.
◦
NULL 무조건 0 byte
◦
TIBERO의 경우 연속 된 NuLL에 대한 크기 부여
col1 | col2 | col3 | BYTE |
NULL | NULL | NULL | 1 + 0 + 0 |
col1 | col2 | col3 | BYTE |
NULL | NULL | 1 | 1 + 1 + type |
col1 | col2 | col3 | BYTE |
NULL | 1 | NULL | 1 + type + |
TIBERO의 경우 NULL 허용 컬럼을 최대한 뒤로 빼는게 TABLE 크기에서 효율적이다.
◦
CUBRID의 경우 데이터 타입의 크기를 미리 할당
INT ⇒ 4 byte / datetime ⇒ 8 byte / VARCHAR, CLOB ⇒ 0 byte
NULL 연산/내부 함수/외부 함수,프로시저
•
NULL 연산
◦
NULL 과 연산되는 모든 값은 NULL로 처리 된다.
•
내부 함수
◦
변환/집계 함수 수학적 연산이 들어가는 함수는 NULL을 배제하고 연산한다.
◦
문자열 접합 함수의 경우 NULL이 들어간 경우 NULL처리 하거나 NULL을 제거하고 접합 한다.
•
외부 함수, 프로시저
◦
함수,프로시저 작성 시 NULL을 고려하지 않으면 의도치 않게 결과가 NULL로 출력 될 수 있다.
NULL 정렬
•
DB 마다 NULL을 정렬 하는 값은 가장 큰 값으로 여기거나 가장 작은 값으로 여겨서 정렬한다.
◦
중간 값은 없다
◦
NULL을 제거하지 않고 정렬하여 값을 얻으려고 할 경우 의도치 않은 NULL이 출력 될 수 있다.
◦
대소 및 MIN/MAX 함수에서는 NULL을 배제 하고 처리한다.
NULL 인덱스
•
DB마다 INDEX에 NULL을 포함하는 경우가 있고 하지 않는 경우가 있다.
◦
싱글/복합 인덱스 구성 시 NULL을 모두 포함거나 경우에 따라 포함한다.
▪
복합 인덱스 구성 시 특정 컬럼이 NOT NULL인 경우 다른 컬럼은 NULL을 포함한다.
◦
싱글/복합 인덱스 모두 NULL을 포함 하지 않는다.
▪
함수 인덱스를 활용하여, 인덱싱 처리를 할 수 있다.
