들어가기 앞서
단위 테스트 스타일 비교
•
출력 기반, 상태 기반, 통신 기반 테스트 스타일에 대해서 알아보자.
함수형 아키텍처와 육각형 아키텍처의 관계
•
출력 기반 스타일로 변환하여 사용하기 위해 함수형 프로그래밍 원칙을 사용해 프로덕션 코드가 함수형 아키텍처를 지향하게끔 구성해야 한다.
•
본 장에서는 함수형 프로그래밍에 관한 내용을 자세히 다루진 않지만, 출력 기반 테스트와 어떻게 관련돼 있는지는 이해할 수 있을 것이다.
출력 기반 테스트로 전환
•
출력 기반 스타일을 사용해 테스트를 작성하는 법에 대해서 알아보자
•
함수형 프로그래밍과 함수형 아키텍처가 지닌 한계에 대해서 알아보자
6.1 단위 테스트의 세 가지 스타일
6.1.1 출력 기반 테스트 정의
출력 기반 스타일은 테스트 대상 시스템(SUT)에 입력을 넣고 생성되는 출력을 점검하는 방식이다.
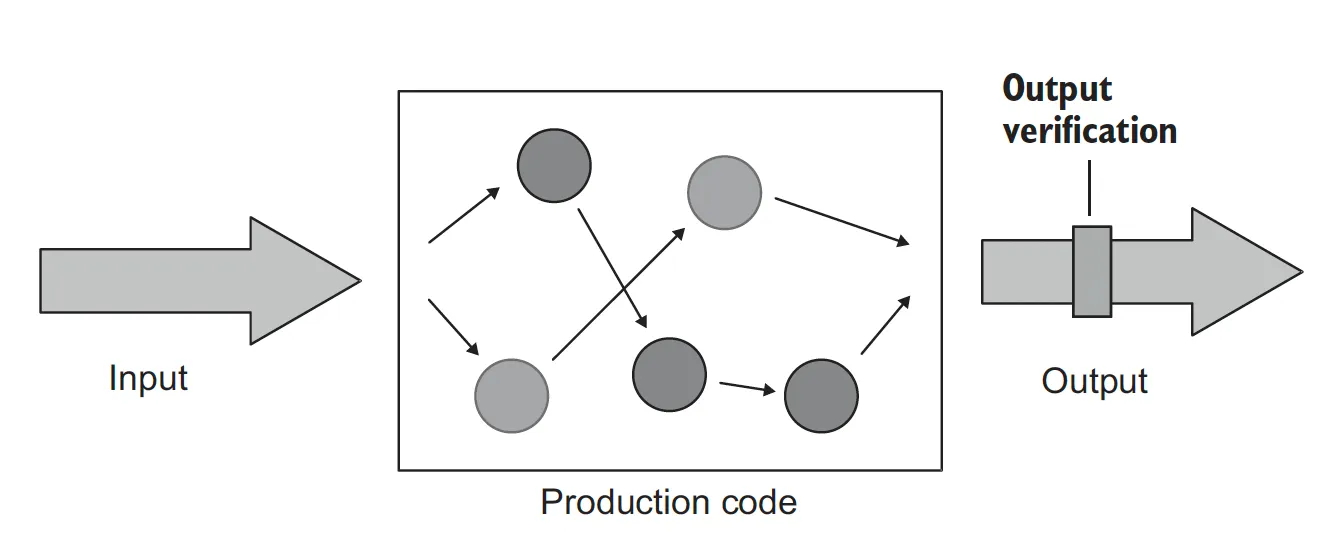
출력 기반 테스트는 시스템이 생성하는 출력을 검증한다. 이러한 테스트 스타일은 부작용이 없고 SUT 작업 결과는 호출자에게 반환하는 값 뿐이다.
// 일련의 상품을 받아 할인을 계산하는 클래스
class PriceEngine {
//상품 수에 1%를 곱하고 그 결과를 20%로 제한하는 함수
fun calculateDiscount(product: List<Product>): Double {
val discount: Double = product.count() * 0.01
return min(discount, 0.2)
}
}
class PriceEngineTest {
@Test
fun discount_of_two_products() {
val product = listOf(
Product.Shampoo,
Product.Book
)
val sut = PriceEngine()
val discount = sut.calculateDiscount(product)
assertEquals(0.02, discount)
}
}
Kotlin
복사
PriceEngine 클래스를 보면 내부에서 상품을 받아 할인만 할 뿐, 내부 컬렉션에 상품을 추가하거나 데이터베이스에 저장하지 않는다. 즉, calculateDiscount 메서드의 결과는 반환된 할인, 출력 값 뿐이다.
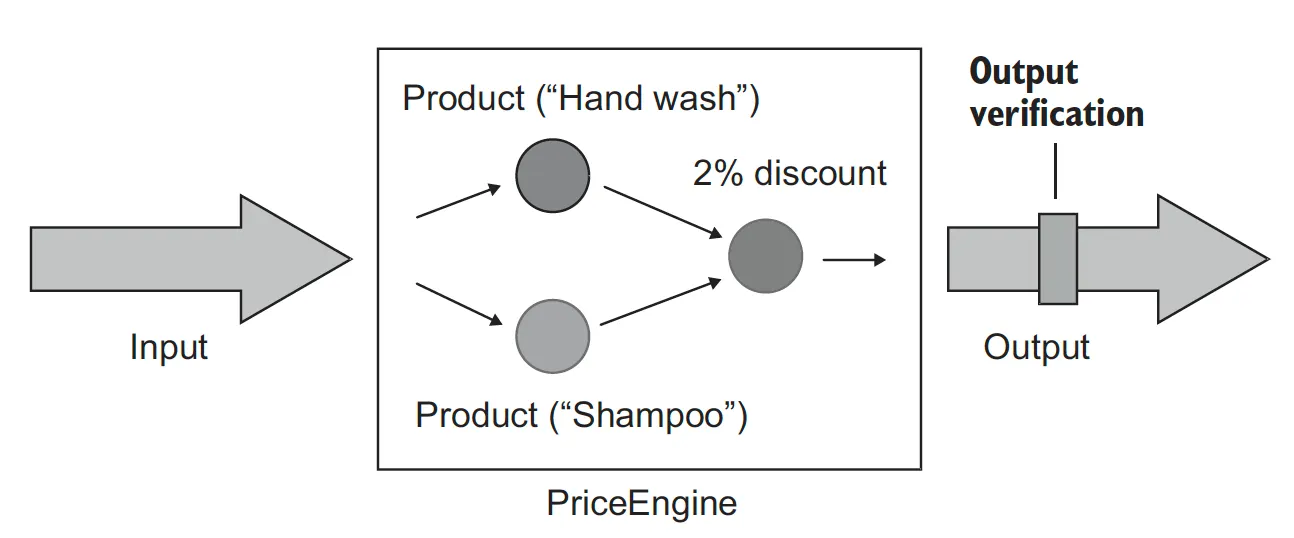
출력 기반 단위 테스트 스타일은 함수형(functional)이라고도 한다. 부작용 없는 코드를 선호하는 프로그래밍 방식인 함수형 프로그래밍(functional programming)에 기반을 둔다.
6.1.2 상태 기반 스타일 정의
상태 기반 스타일은 작업이 완료된 후에 시스템의 상태를 확인한다.
여기서 “상태”라는 용어는 SUT, 협력자, 또는 데이터베이스나 파일 시스템 등과 같은 프로세스 외부 의존성의 상태를 뜻한다.
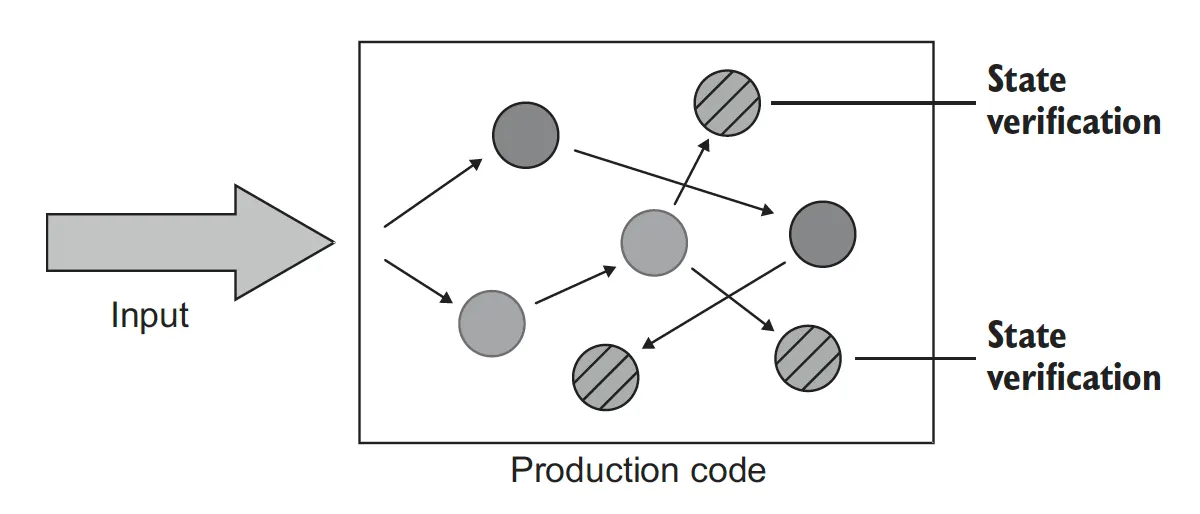
상태 기반 테스트는 작업이 완료된 후, 시스템의 최종 상태를 검증한다. 빗금이 그려진 원이 최종 상태를 나타낸다.
class Order {
private val _product = mutableListOf<Product>()
val product = _product
fun addProduct(product: Product) {
//상품을 추가한 후 _product 상태 변경
_product.add(product)
}
}
class OrderTest {
@Test
fun adding_a_product_to_an_order() {
val product = Product.Shampoo
val sut = Order()
sut.addProduct(product)
// 상태가 변경된 후 작업이 잘 완료 되었는지 검증
assertEquals(1, sut.product.count())
assertEquals(product, sut.product[0])
}
}
Kotlin
복사
위의 테스트는 상품을 추가한 후 product 컬렉션을 검증한다. 출력 기반 테스트와 달리, addProduct 메서드의 결과는 주문 상태의 변경이다.
6.1.3 통신 기반 스타일 정의
통신 기반 스타일은 목을 사용해 테스트 대상 시스템과 협력자 간의 통신을 검증한다.
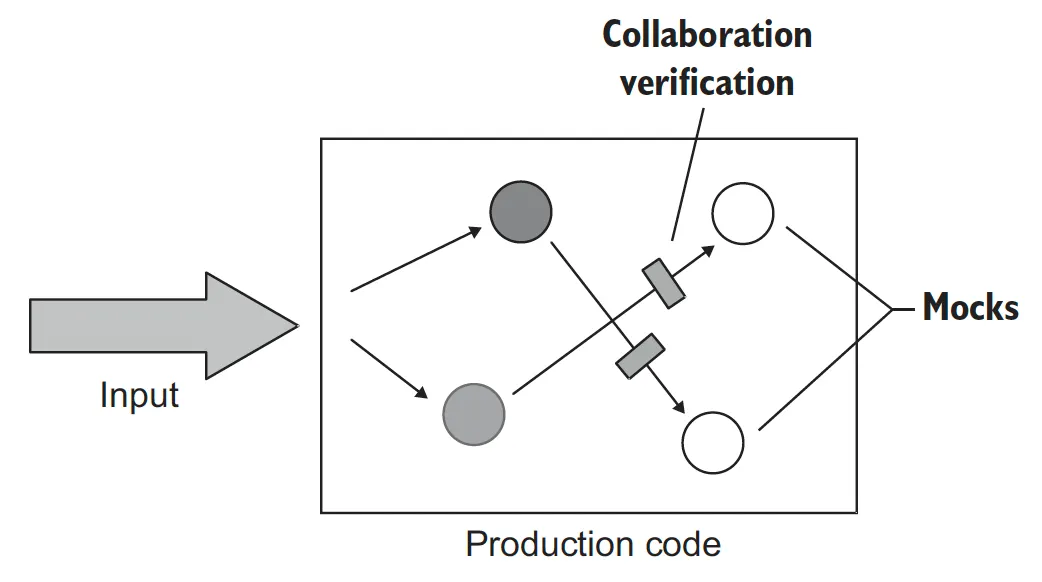
통신 기반 테스트는 SUT의 협력자를 목으로 대체하고 SUT가 협력자를 올바르게 호출 하는지 검증한다.
class ControllerTest {
@Test
fun sending_a_greetings_email() {
//mock을 사용해 sut에 대해서 검증
val emailGateWay = mock(IEmailGateway::class.java)
val sut = Controller(emailGateWay)
sut.greetUser("jun@email.com")
verify(emailGateWay, times(1))
}
}
Kotlin
복사
6.2 단위 테스트 스타일 비교
출력, 상태, 통신 기반 단위 테스트 스타일과 좋은 단위 테스트의 4대 요소로 비교하면서 살펴보자.
•
회귀 방지
•
리팩터링 방지
•
빠른 피드백
•
유지 보수성
6.2.1 회귀 방지와 피드백 속도 지표로 스타일 비교하기
회귀 방지와 빠른 피드백 특성은 비교하기 좋기 때문에 같이 살펴보자.
회귀 방지 지표는 특정 스타일에 따라 달라 지지 않는다.
•
테스트 중에 실행되는 코드의 양
•
코드 복잡도
•
도메인 유의성
코드의 양, 코드 복잡도, 도메인 유의성 모두, 관련 없이 원하는 대로 테스트를 작성할 수 있다. 즉, 어떤 스타일도 도움이 되지 않는다.
물론 통신 기반 스타일을 사용할 때 기술을 남용하여(ex: 모든 것을 목으로 대체 …) 테스트하면 영향이 있을 순 있지만, 이는 극단적인 사례이다.
테스트 피드백 속도도 테스트 스타일과 상관관계가 거의 없다.
테스트가 단위 테스트 영역에 있는 한, 모든 스타일은 테스트 실행 속도가 거의 동일하다. 통신 기반 스타일에서 목을 사용하면 런타임에 지연 시간이 생기긴 하겠지만, 이는 테스트가 수만 개 수준이 아니라면 별로 차이가 없다.
6.2.2 리팩터링 내성 지표로 스타일 비교하기
리팩터링 내성은 리팩터링 중에 발생하는 거짓 양성 수에 대한 척도이다. 즉, 거짓 양성은 식별할 수 있는 동작이 아닌 코드의 구현 세부 사항에 결합된 테스트의 결과이다.
출력 기반 테스트
이 스타일은 테스트 대상 메서드에서만 결합되므로 거짓 양성 방지가 가장 우수하다.
이러한 테스트가 구현 세부 사항에 결합되는 경우는 테스트 대상 메서드가 구현 세부 사항일”때” 뿐이다
// 클라이언트가 알아도 된다면? 구현 세부 사항 x
// 만약 구현 세부 사항이야? 그러면 당연히 구현 세부 사항 o
fun comma(input: Int): String {
//세 자리마다 콤마 찍기
}
@Test
fun test() {
val sut = Test()
val result = sut.comma()
}
Kotlin
복사
상태 기반 테스트
이 스타일은 일반적으로 거짓 양성이 되기 쉽다. 이러한 테스트는 테스트 대상 메서드 외에도 클래스 상태와 함께 작동한다.
상태 기반 테스트는 큰 API 노출 영역(ex: 외부 데이터베이스)에 의존하므로, 구현 세부 사항과 결합할 가능성이 높다.
통신 기반 테스트
이 스타일이 허위 경보에 가장 취약하다. 테스트 대역(mock)으로 상호 작용을 확인하는 테스트는 대부분 깨지기 쉽다. 애플리케이션 경계를 넘는 상호 작용을 확인하거나 해당 상호 작용의 side-effect가 외부 환경에 보이는 경우(ex: 외부 의존성과 상호작용 후 근데 side-effect 있었음. side-effect와 관련된 변수가 노출되는 경우)에는 목을 사용해도 좋다.
위의 세 가지 스타일을 사용할 때 주의사항을 살펴봤다. 하지만 가장 중요한 것은 캡슐화를 잘 지키고 테스트를 식별할 수 있는 동작에만 결합하여 거짓 양성을 최소로 줄이도록 노력하는 것이다.
6.2.3 유지 보수성 지표로 스타일 비교하기
유지 보수성 지표는 단위 테스트 스타일과 밀접한 관련이 있다. 하지만 리팩터링 내성과 달리 완화할 수 있는 방법은 많지 않다.
•
테스트를 이해하기 얼마나 어려운가(테스트 크기에 대한 함수)
•
테스트를 실행하기 얼마나 어려운가(테스트에 직접적으로 관련 있는 프로세스 외부 의존성 개수에 대한 함수)
테스트가 크다 → 필요할 때 파악하기도 변경하기도 어려우므로 유지 보수가 쉽지 않다.
여러 개의 프로세스 외부 의존성(ex: DB) → 하나 이상의 프로세스 외부 의존성과 직접 작동하는 테스트는 DB 서버 재부팅, 네트워크 연결 문제 등과 같이 운영하는 데 시간이 필요하므로 유지 보수가 쉽지 않다.
출력 기반 테스트
출력 기반 테스트는 항상 짧고 간결하므로(메서드로 입력을 공급하는 것, 해당 출력을 검증하는 것 뿐) 유지 보수에 용이하다.
또한, 전역 상태나 내부 상태를 변경할 리 없으므로, 프로세스 외부 의존성을 다루지 않는 장점도 있다.
상태 기반 테스트
상태 검증은 출력 검증보다 더 많은 공간을 차지하기 때문에 유지 보수가 쉽지 않다.
@Test
fun adding_a_comment_to_an_article() {
val sut = Article()
val text = "Comment Text"
val author = "John Doe"
val now = LocalDate.of(2022, 10, 31)
sut.addComment(text, author, now)
assertEquals(1, sut.comments.count())
assertEquals(text, sut.comments[0].text)
assertEquals(author, sut.comments[0].author)
assertEquals(now, sut.comments[0].dateCreated)
}
Kotlin
복사
위의 테스트는 글에 댓글을 추가한 후 댓글 목록에 댓글이 나타나는지 확인한다. 단순한 댓글 치고는 검증문이 많은 것을 확인할 수 있다. 상태 기반 테스트는 종종 훨씬 많은 데이터를 확인해야 하므로 크기가 커질 수 있다.
헬퍼 메서드로 문제를 완화할 수 있지만, 이러한 메서드를 작성하고 유지하는 데 상당한 비용이 든다. 특정 메서드를 재사용 할 때는 유용 하겠지만, 그런 경우는 드물다(해당 책의 3부에서 자세히 설명).
@Test
fun adding_a_comment_to_an_article() {
val sut = Article()
val text = "Comment Text"
val author = "John Doe"
val now = LocalDate.of(2022, 10 ,31)
sut.addComment(text, author, now)
sut.shouldContainNumberOfComments(sut, 1)
.withComment(sut, text, author, now)
}
fun Article.shouldContainNumberOfComments(
article: Article, commentCount: Int,
): Article {
assertEquals(1, article.comments.count())
return article
}
fun Article.withComment(
article: Article,
text: String,
author: String,
dateCreated: LocalDate,
): Article {
val comment: Comment = article.comments.single { x ->
x.text == text && x.author == author && x.dateCreated == dateCreated
}
assertNotNull(comment)
return article
}
Kotlin
복사
또 다른 방법으로, 검증 대상 테스트의 동등 멤버를 정의할 수 있다. 즉, 인스턴스를 참조하는 것이 아닌 값으로 비교할 수 있다.
class Article {
private val _comments = mutableListOf<Comment>()
val comments: List<Comment> = _comments
fun addComment(text: String, author: String, now: LocalDate) {
_comments.add(Comment(text, author, now))
}
fun shouldContainNumberOfComments(i :Int): Article {
return this
}
}
@Test
fun adding_a_comment_to_an_article() {
val sut = Article()
val comment = Comment(
text = "Comment Text",
author = "John Doe",
dateCreated = LocalDate.of(2022, 10 ,31)
)
sut.addComment(comment.text, comment.author, comment.dateCreated)
assertThat(comment, allOf(`is`(sut.comments[0])))
}
Kotlin
복사
위의 테스트에서는 댓글을 개별 속성으로 지정하지 않고 전체 값으로 비교하는 것을 볼 수 있다. 물론 좋은 방법이지만, 클래스가 값에 해당하고 값 객체로 변환할 수 있을 때만 효과적이다. 이를 남용하면 코드 오염(단지 단위 테스트를 가능하게 하기 위해 프로덕션 코드를 오염시키는 것)이 이어진다.
이렇게 해결을 할 순 있지만, 코드를 추가해주는 비용 또는 크기가 증가하므로 출력 기반 테스트 스타일 보단 유지보수성이 떨어진다.
통신 기반 테스트
세 가지 스타일 중 유지 보수성이 가장 떨어진다.
통신 기반 테스트에는 테스트 대역과 상호 작용 검증을 설정해야 하며, 이는 공간을 많이 차지한다. 특히, 목이 chain 형태로 구성되어 있으면 테스트는 더 커지고 유지 보수하기가 어려워진다.
6.2.4 스타일 비교하기: 결론
출력 기반 | 상태 기반 | 통신 기반 | |
리팩터링 내성을 지키기 위해 필요한 노력 | 낮음 | 중간 | 중간 |
유지비 | 낮음 | 중간 | 높음 |
앞서 살펴봤듯이, 출력 기반 테스트가 가장 결과가 좋다. 구현 세부 사항과 결합되지 않아 리팩터링 내성에 크게 신경 쓰지 않아도 되고, 간결하고 프로세스 외부 의존성이 없기 때문에 유지 보수도 용이하다.
상태 & 통신 기반 테스트는 유출되는 구현 세부 사항에 결합할 가능성이 높고, 크기도 커서 유지비가 많이 들기 때문에 지표가 좋지 않다.
어? 그렇다면 출력 기반 테스트 스타일만 사용하면 무조건 좋은 것이 아닌가? 하지만 이해하고 말하기는 쉬워도 행하기는 어렵다. 출력 기반 테스트는 함수형으로 작성된 코드에만 적용할 수 있고, 대부분의 객체지향 프로그래밍 언어에는 해당되지 않는다.
이제 상태 & 통신 기반 테스트에서 출력 기반 테스트로 바꾸는 법을 배워보자.
6.3 함수형 아키텍처 이해
6.3.1 함수형 프로그래밍이란?
함수형 프로그래밍은 수학적 함수(순수 함수라고도 함)를 사용한 프로그래밍이다. 수학적 함수는 숨은 입출력이 없는 함수다. 수학적 함수의 모든 입출력은 메서드 이름, 인수, 반환 타입으로 구성된 메서드 시그니처에 명시해야 한다. 즉, 수학적 함수는 호출 횟수에 상관없이 주어진 입력에 대해 동일한 출력을 생성한다.

순수함수(Pure function)
- 동일한 입력에는 항상 같은 값을 반환해야 하는 함수
- 함수의 실행이 프로그램의 실행에 영향을 미치지 않아야 하는 함수
- 함수 내부에서 인자의 값을 변경하거나 프로그램 상태를 변경하는 sdie effect가 없는 것
fun calculateDiscount(product: List<Product>): Double {
val discount: Double = product.count() * 0.01
return min(discount, 0.2)
}
Kotlin
복사
calculateDiscount 메서드는 하나의 입력(product)과 하나의 출력(discount)이 있으며, 둘 다 메서드 시그니처에 명시돼 있다. 즉, calculateDiscount 는 수학적 함수가 된다.


그림 1
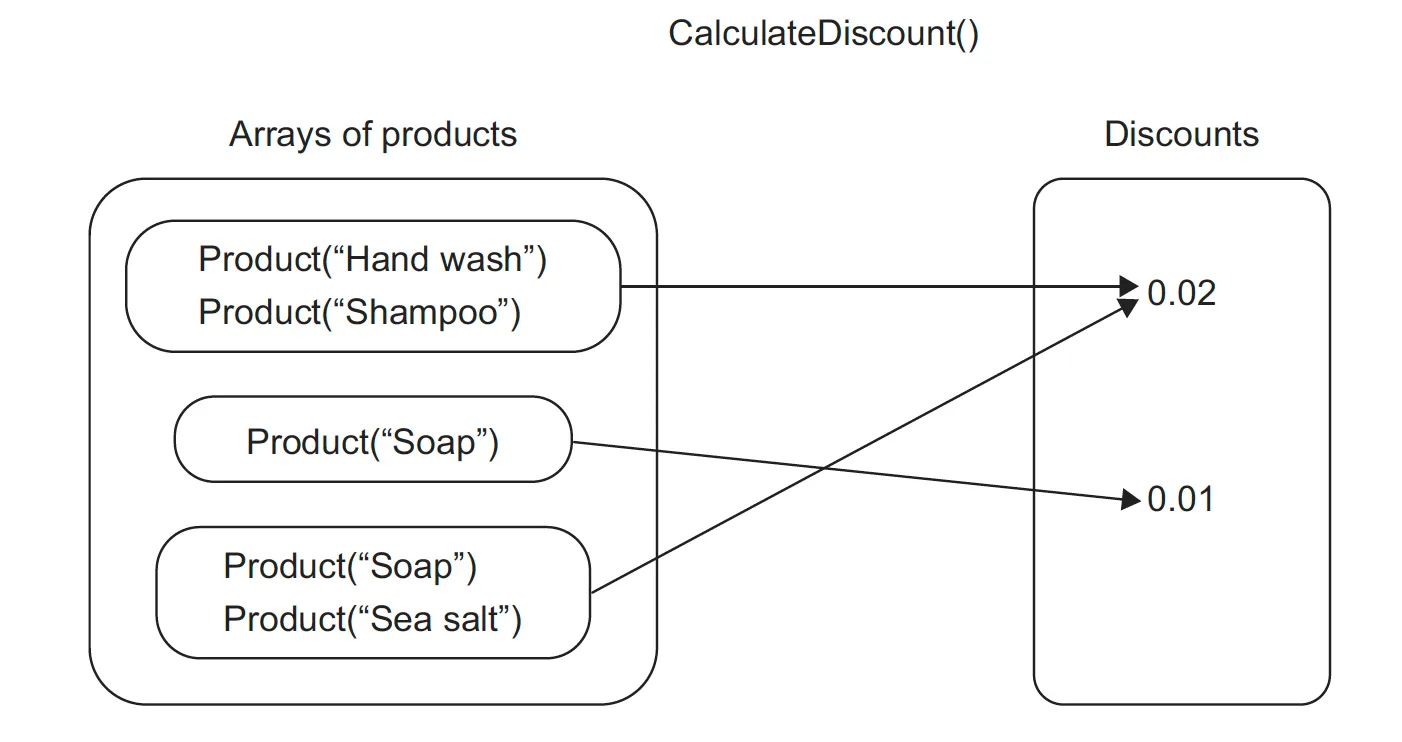
그림 2
그림 1을 보면 을 통해, 집합 X의 각 입력 수 x에 대해 함수는 집합 Y의 해당하는 수 y를 찾는다.
그림 2도 함수의 연산만 다를 뿐이지 같은 것을 볼 수 있다. 즉, 상품의 각 입력에 대해 해당 할인을 calculateDiscount 함수를 통해 출력으로 찾는다.
입출력을 명시한 수학적 함수의 이점
•
테스트가 짧고 간결하며 이해하기 쉽고 유지보수 하기 쉬우므로 테스트가 쉽다.
•
출력 기반 테스트를 적용할 수 있는 것은 수학적 함수 뿐이다. 즉, 유지보수성이 뛰어나고 거짓 양성 빈도가 낮다.
숨은 입 출력을 가진 코드에 대한 테스트
•
부작용(side effect) → 메서드 시그니처에 표시되지 않은 출력, 즉 숨어있다. 연산은 클래스 인스턴스의 상태를 변경하고 파일을 업데이트 하는 등 부작용을 야기한다.
•
예외 → 호출된 예외는 호출 스택의 어느 곳에서도 발생할 수 있으므로, 메서드 시그니처가 전달하지 않는 출력을 추가한다.
•
내외부 상태에 대한 참조 → LocalDate.now() 와 같이 정적 속성을 사용해 값을 가져오는 메서드가 있다. DB에서 데이터를 질의하거나 비공개 변경 가능 필드를 참조할 수도 있다. 즉, 모두 메서드 시그니처에 없는 실행에 대한 입력이며, 숨어있다.
그렇다면 사용하고자 하는 메서드가 수학적 함수인지 어떻게 판별해야 할까?
가장 좋은 방법은 프로그램의 동작을 변경하지 않고 해당 메서드에 대한 호출을 반환 값으로 대체할 수 있는지 확인하는 것이다(참조 투명성).
참조 투명성
참조 투명성은 함수(또는 메서드)가 함수의 외부의 영향을 받지 않는 것을 의미한다. 다른 말로, 함수의 결과는 입력 파라미터에만 의존하고 함수의 외부에 있는 입력 콘솔, 파일, 원격 URL, DB, 파일 시스템 등에서 데이터를 읽지 않는다. 함수 외부의 값을 변경하거나, 외부 의존성에 의존적이지 않는 코드를 가리켜 “참조 투명성이 있다”라고 한다.
//수학적 함수를 사용한 예
fun increment(x: Int): Int {
return x.plus(1)
}
fun main() {
val y = increment(4)
// y = 5
}
Kotlin
복사
//수학적 함수가 아닌 예
var x = 0
fun increment(): Int {
x++
return x
}
Kotlin
복사
위의 예제 코드를 살펴보면 쉽게 알 수 있다. 수학적 함수를 사용한 예제 코드를 보면 입력을 받아 plus 함수를 사용해 동일한 동작에 대한 출력 값을 보내는 것을 알 수 있다.
반면에 수학적 함수가 아닌 예제 코드를 보면, 반환 값이 메서드의 출력을 모두 나타내지 않으므로 반환 값으로 대체할 수 없다. 즉, 숨은 출력은 전역 필드 x의 변경(side effect)이다.
6.3.2 함수형 아키텍처란?
당연히 어떤 부작용도 일으키지 않는 애플리케이션을 만들 순 없다. 부작용은 사용자 정보 업데이트, 물품 구매, 판매 등 모든 애플리케이션에서 발생한다.
함수형 프로그래밍의 목표는 부작용을 완전히 없애는 것이 아닌, 비즈니스 로직을 처리하는 코드와 부작용을 일으키는 코드를 분리하는 것이다. 부작용을 비즈니스 연산 끝으로 몰아서 비즈니스 로직을 부작용과 분리하자.
•
결정을 내리는 코드(함수형 코어 or 불변 코어) → 이 코드는 부작용이 필요 없기 때문에 수학적 함수를 사용해 작성할 수 있다.
•
해당 결정에 따라 작용하는 코드(가변 셸) → 이 코드는 수학적 함수에 의해 이뤄진 모든 결정을 DB의 변경이나 메시지 버스로 전송된 메시지와 같이 가시적인 부분으로 변환한다.
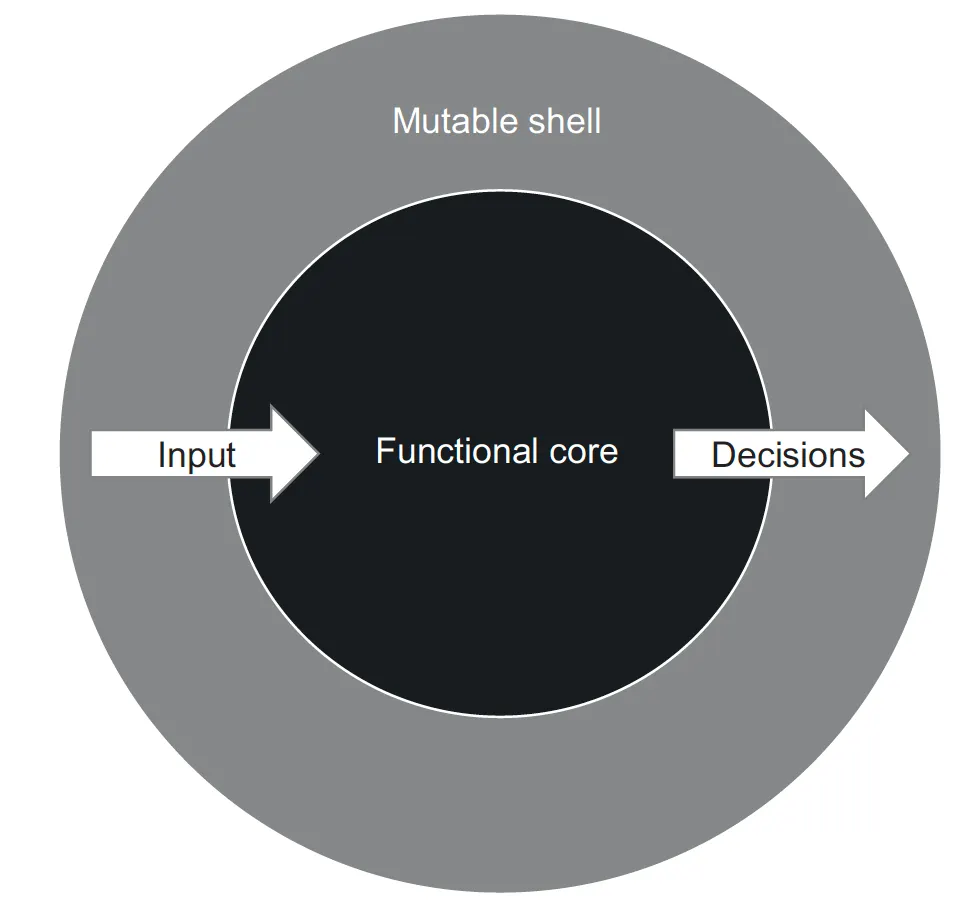
함수형 아키텍처에서 함수형 코어는 수학적 함수를 사용해 구현되며 애플리케이션에서 모든 결정을 내린다.
가변 셸은 함수형 코어에 입력 데이터를 제공하고 DB와 같은 프로세스 외부 의존성에 부작용을 적용해 그 결정을 해석한다.
함수형 코어와 가변 셸은 어떻게 분리(협력)해서 사용해야 할까?
•
가변 셸은 모든 입력을 수집한다.
•
함수형 코어는 결정을 생성한다.
•
가변 셸은 결정을 부작용으로 변환한다.
가변 셸은 의사 결정을 추가하지 않게끔 결정을 나타내는 클래스에 정보가 충분히 있는지 확인해야 한다.
함수형 아키텍처의 목표는 출력 기반 테스트로 함수형 코어를 다루고, 가변 셸을 훨씬 더 적은 수의 통합 테스트에 맡기는 것이다.
6.3.3 함수형 아키텍처와 육각형 아키텍처 비교
육각형 아키텍처와 함수형 아키텍처의 주된 관심사는 분리이다.

육각형 아키텍처는 도메인 계층과 애플리케이션 서비스 계층을 구별한다. 도메인 계층은 비즈니스 로직에 책임이 있고, 애플리케이션 서비스 계층은 외부 애플리케이션과의 통신에 책임으로 분리되어 있다.
이는, 결정과 실행을 분리하는 함수형 아키텍처와 매우 유사하다.
도메인 계층 → 함수형 코어 / 애플리케이션 서비스 → 가변 셸
의존성 간의 단방향 흐름 관점에서도 유사하다.
육각형 아키텍처에서 도메인 계층 내 클래스는 서로에게만 의존해야 하고, 애플리케이션 서비스에 의존해서는 안된다.
함수형 아키텍처의 함수형 코어(불변 코어)는 가변 셸에 의존하지 않는다. 자급할 수 있고 외부 계층과 격리돼 작동할 수 있다. 이로 인해 테스트 하기 용이하다.
육각형과 함수형 아키텍처 간 유일한 차이점은 부작용에 대한 처리에 있다.
함수형 아키텍처는 모든 부작용을 함수형 코어에서 비즈니스 연산 가장자리로 밀어낸다. 이 가장 자리는 가변 셸이 처리한다.
육각형 아키텍처의 모든 수정 사항은 도메인 계층 내에 있어야 하며, 계층의 경계를 넘어서는 안된다. 예를 들어, 도메인 클래스 인스턴스는 DB에 직접 저장할 순 없지만, 상태는 변경할 수 있다. 애플리케이션 서비스에서 이 변경 사항을 DB에 직접 적용한다.
6.4 함수형 아키텍처와 출력 기반 테스트로의 전환
이제 예제 애플리케이션을 함수형 아키텍처로 리팩터링 해보자.
•
프로세스 외부 의존성에서 목으로 변경
•
목에서 함수형 아키텍처로 변경
두 가지 리팩터링 단계를 거쳐 상태 & 통신 기반 테스트를 출력 기반 스타일로 리팩터링 할 것이다.
6.4.1 감사 시스템 소개
예제 프로젝트에서 대해서 간략하게 설명하겠다.
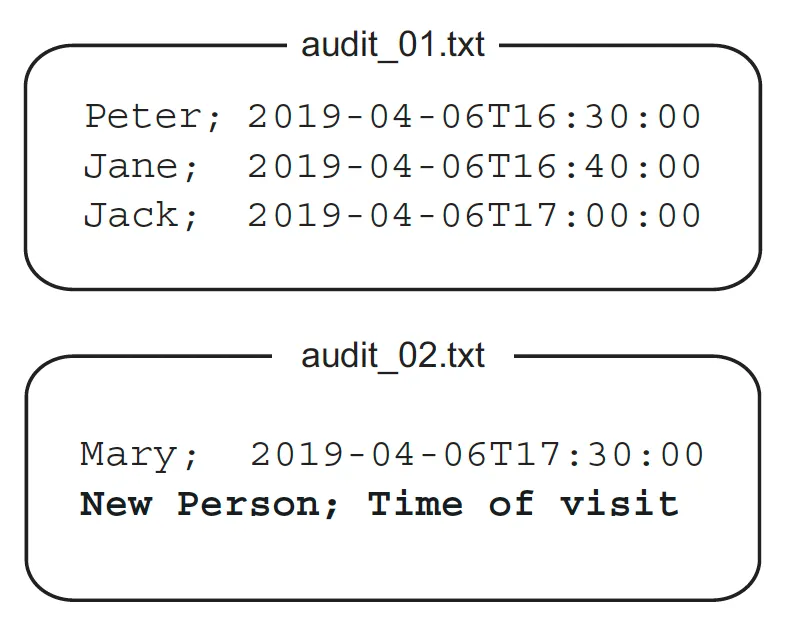
주 도메인은 조직의 모든 방문자를 추적하는 감사 시스템이다.
이 시스템은 가장 최근 파일의 마지막 줄에 방문자의 이름과 방문 시간을 추가한다.
파일당 최대 항목 수에 도달하면 인덱스를 증가시켜 새 파일을 작성한다.
before 예제 코드
•
작업할 폴더 경로에서 전체 파일 목록을 검색한다.
•
인덱스별로 정렬한다 → 모든 파일 이름은 audit_${index}.txt 패턴을 따른다.
•
감사 파일이 하나도 없으면 첫 번째 파일을 생성하고 새로운 레코드를 작성한다.
•
감사 파일이 있으면 최신 파일(정렬된 파일의 가장 마지막)을 가져와서 항목 수(3줄 이하)가 한계에 도달 했는지에 따라 새로운 레코드를 추가하거나 새 파일을 생성한다.
◦
3줄 이하 → 최신 파일의 모든 라인을 읽어 아래에 새로운 레코드를 추가
◦
3줄 이상 → 새로운 파일을 추가하고 새로운 레코드를 추가
초기 버전 애플리케이션의 AuditManager 클래스는 파일 시스템과 밀접하게 연결돼 있어 테스트 하기가 매우 어렵다.
테스트 전에 파일을 올바른 위치에 배치하고, 테스트가 끝나면 해당 파일을 읽고 내용을 확인한 후 삭제해야 한다.
파일 시스템은 병목 지점을 나타낸다. 이는 테스트가 실행 흐름을 방해할 수 있는 공유 의존성이다.
또한, 파일 시스템은 테스트를 느리게 한다. 로컬 시스템과 빌드 서버 모두 작업 폴더가 있고 테스트할 수 있어야 하므로 유지 보수성도 저하된다.
초기 버전 | |
회귀 방지 | 좋음 |
리팩터링 내성 | 좋음 |
빠른 피드백 | 나쁨 |
유지 보수성 | 나쁨 |
근본적인 문제점을 살펴보면, 파일 시스템을 직접 작동하는 테스트는 단위 테스트 정의에 맞지 않는다.
•
단위 테스트는 단일 동작 단위를 검증한다.
•
빠르게 수행한다 → 파일 시스템과 맞지 않음
•
다른 테스트와 별도로 처리한다 → 파일 시스템과 맞지 않음
6.4.2 테스트를 파일 시스템에서 분리하기 위한 목 사용
테스트가 밀접하게 결합된 문제는 일반적으로 파일 시스템을 목으로 처리해 해결한다.
파일의 모든 연산을 IFileSystem 인터페이스로 도출한 후 AuditManager 클래스에 IFileSystemImpl구현 클래스를 주입 받아 사용할 수 있다.
그 후, 테스트는 IFileSystemImpl 클래스를 목으로 처리하고 감사 시스템이 파일에 수행하는 쓰기를 캡처한다.

mock 예제 코드
목 버전 테스트 코드를 보면 목을 타당하게 사용하는 것을 알 수 있다. 애플리케이션은 최종 사용자가 볼 수 있는 파일을 생성한다(목을 사용해서 파일을 추가하고 읽는 행동을 유추).
따라서 파일 시스템과의 통신과 이러한 통신의 부작용(파일 변경)은 애플리케이션의 식별할 수 있는 동작이다.
목 버전은 초기 버전 보다 개선된 것을 알 수 있다.
테스트는 더 이상 파일 시스템에 접근하지 않으므로 더 빨리 실행된다. 또한, 파일 시스템을 다룰 필요가 없으므로 유지비도 절감된다. 리팩터링을 해도 회귀 방지와 리팩터링 내성이 나빠지지 않았다.
초기 버전 | 목 사용 | |
회귀 방지 | 좋음 | 좋음 |
리팩터링 내성 | 좋음 | 좋음 |
빠른 피드백 | 나쁨 | 좋음 |
유지 보수성 | 나쁨 | 중간 |
하지만 더욱 개선할 점들이 보인다. 목 테스트는 복잡한 설정(whenever 사용하여 원하는 반환 값 설정 등)을 포함하기 때문에 유지비 측면에서 이상적이지 않다. 또한, 일반적인 입출력에 의존하는 테스트만큼 가독성이 좋지 않다.
6.4.3 함수형 아키텍처로 리팩터링하기
부작용을 클래스 외부로 완전히 이동시키자. 그러면 AuditManager 클래스는 파일에 수행할 작업을 둘러싼 결정만 책임지게 된다. 새로운 클래스인 Persister 는 그 결정에 따라 파일 시스템에 업데이트를 적용한다.
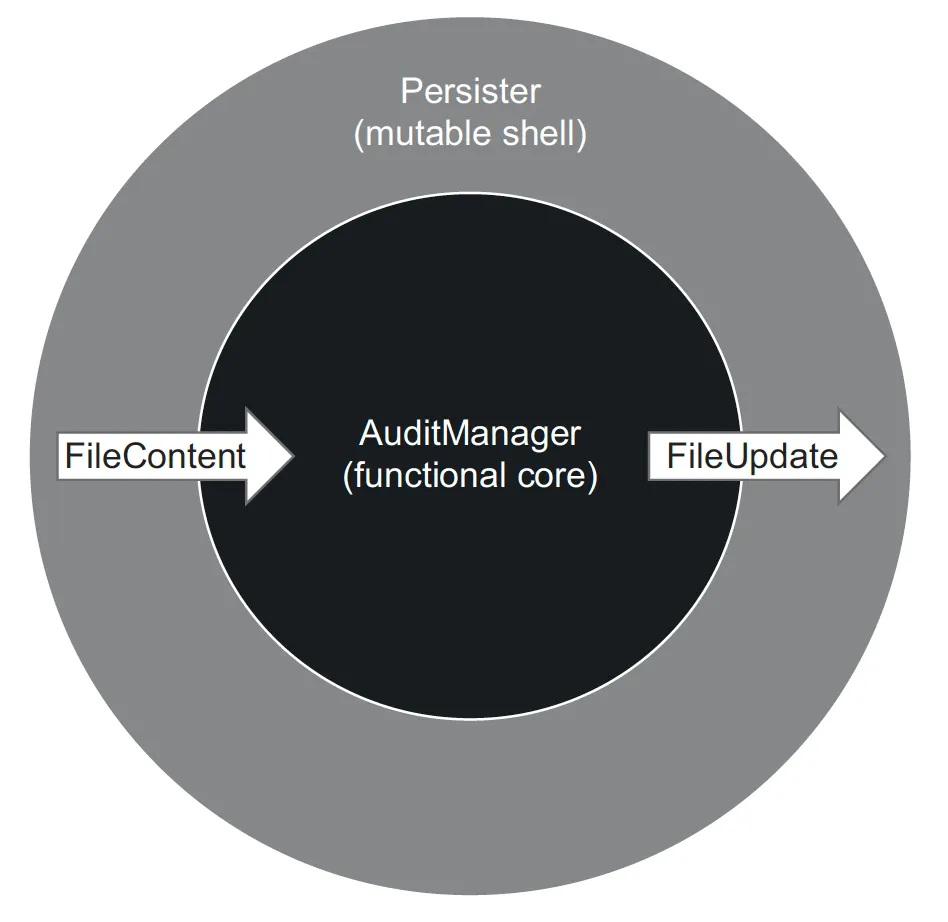
Persister 클래스는 작업 폴더에서 파일과 해당 내용을 수집해 AuditManager 클래스에 준 다음, 반환 값을 파일 시스템의 변경 사항으로 변환한다.
functional 예제 코드
Persister 클래스를 보면 분기 문이 없는 것을 확인할 수 있다. 따라서 모든 복잡도는 AuditManager 클래스에 있다. 이것이 비즈니스 로직과 부작용의 분리이다.
이렇게 분리된 Persister 와 AuditManager 클래스를 붙이려면 애플리케이션 서비스 클래스가 필요하다.
ApplicationService 는 함수형 코어와 가변 셸을 붙이면서 애플리케이션 서비스가 외부 클라이언트를 위한 시스템의 진입점을 제공한다.
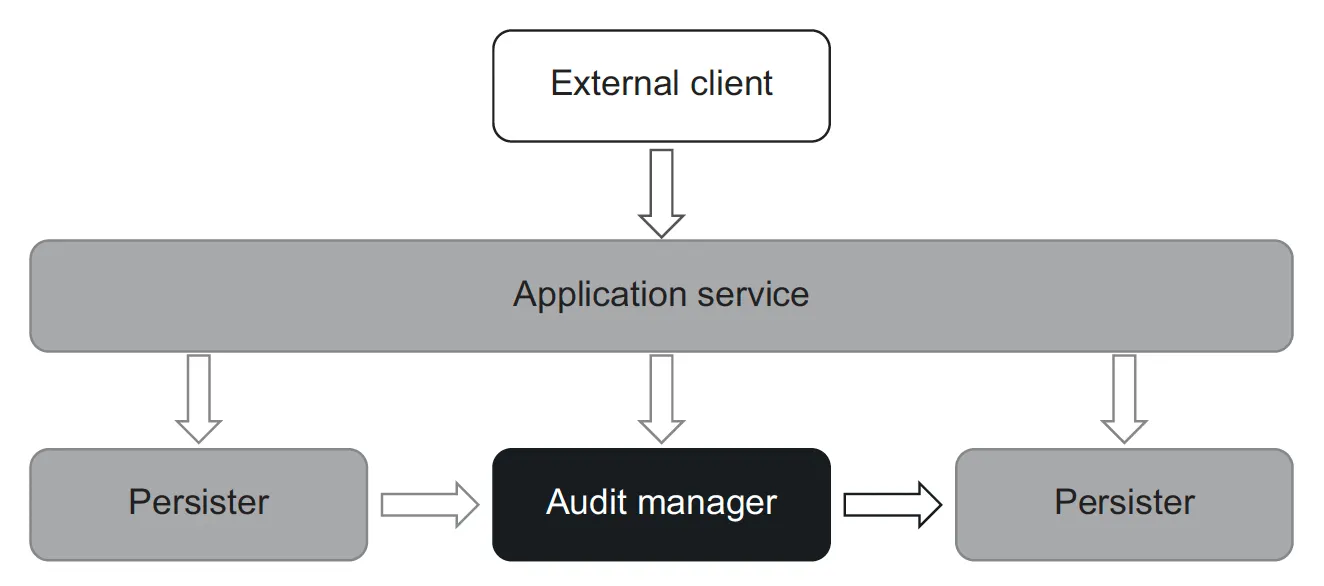
함수형 아키텍처를 사용한 테스트를 보면 빠른 피드백과 유지 보수성도 향상된다. 더 이상 복잡한 목 설정이 필요 없고, 단순한 입출력만 필요하므로 테스트 가독성도 향상 시켰다.
초기 버전 | 목 사용 | 출력 기반 | |
회귀 방지 | 좋음 | 좋음 | 좋음 |
리팩터링 내성 | 좋음 | 좋음 | 좋음 |
빠른 피드백 | 나쁨 | 좋음 | 좋음 |
유지 보수성 | 나쁨 | 중간 | 좋음 |
6.5 함수형 아키텍처의 단점 이해하기
함수형 아키텍처가 좋다고 해서 언제나 사용할 수 있는 것은 아니다. 또한 함수형 아키텍처라고 해도, 코드베이스가 커지고 성능에 영향을 미치면서 유지 보수성의 이점을 상쇄할 수도 있다.
6.5 절에서는 함수형 아키텍처와 관련된 비용과 장단점에 대해서 살펴보자.
6.5.1 함수형 아키텍처 적용 가능성
이전에 살펴본 감사 시스템은 결정을 내리기 전에 입력을 모두 미리 수집할 수 있으므로 함수형 아키텍처에 적합했다. 하지만 만약 의사 결정 절차의 중간 결과에 따라 프로세스 외부 의존성에서 추가 데이터를 질의한다면??
예를 들어, 지난 24시간 동안 방문 횟수가 임계치를 초과하면 감사 시스템이 방문자의 접근 레벨을 확인해야 한다고 해보자.
•
방문자의 접근 레벨이 모두 DB에 저장돼 있음
fun addRecord(
files: List<FileContent>,
visitorName: String,
timeOfVisit: LocalDate,
database: IDatabase
) : FileUpdate
Kotlin
복사
addRecord 메서드는 이제 숨은 입력이 생겼다. 따라서 이 메서드는 수학적 함수가 될 수 없으며, 더이상 출력 기반 테스트를 적용할 수 없다.
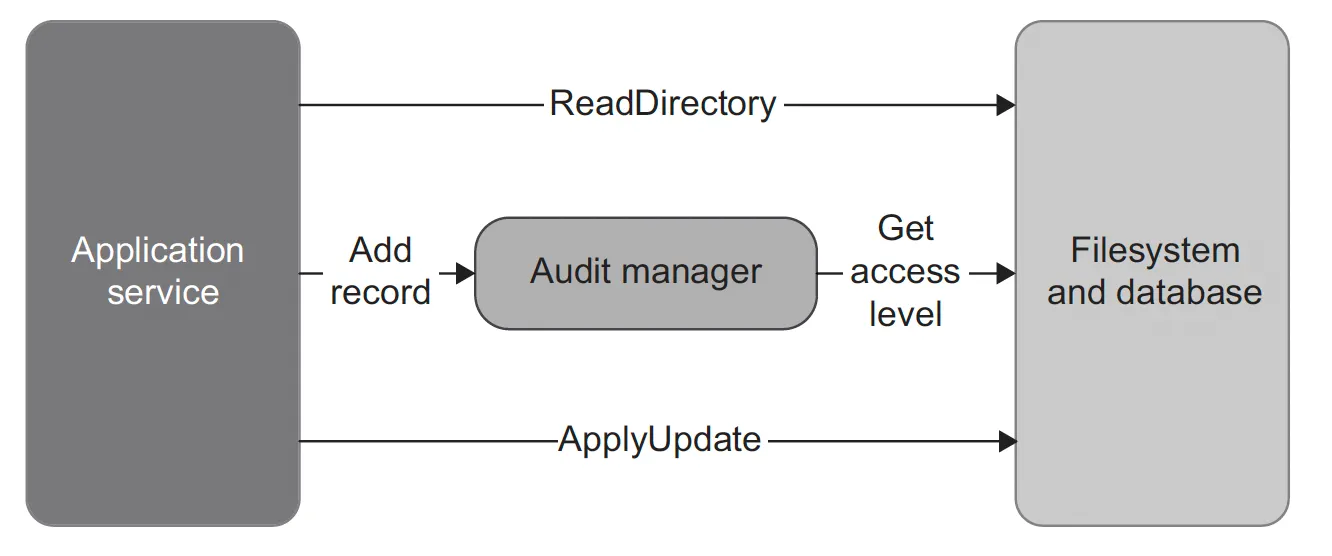
데이터베이스에 대한 의존성으로 인해 감사 관리자에 숨은 입력이 생겼다. 이러한 클래스는 더 이상 순수 함수가 아니며, 전체 애플리케이션은 더 이상 함수형 아키텍처를 따르지 않는다.
문제점을 해결하고자 두 가지 해결책을 제안할 수 있다.
•
애플리케이션 서비스 전면에서 디렉터리 내용과 방문자 접근 레벨을 수집
•
AuditManager에서 접근 레벨을 확인 여부에 대한 새로운 메서드를 생성한다. 애플리케이션 서비스에서 addRecord 호출하기 전에 새로운 메서드를 호출하여 true를 반환하면 데이터베이스에서 접근 레벨을 가져온 후 addRecord에 전달
첫 번째 방법은 접근 레벨이 필요 없는 경우에도 무조건 DB에 질의하기 때문에 성능이 저하된다. 하지만 비즈니스 로직과 외부 시스템과의 통신을 완전히 분리시킬 수 있는 장점이 있다.
두 번째 방법은 성능 향상을 위해 분리를 다소 완화한다는 점이다. DB를 호출하는지에 대한 결정을 도메인 모델이 아닌 애플리케이션 서비스로 넘긴다.
두 가지 해결책과 달리, 도메인 모델(AuditManager)을 DB에 의존하는 것은 좋은 생각이 아니다. 7, 8장에서는 관심사 분리와 성능 간의 균형을 지키는 것에 대해 자세히 설명한다.
6.5.2 성능 단점
함수형 아키텍처와 전통적인 아키텍처 사이의 선택은 성능과 코드 유지 보수성(프로덕션 코드, 테스트 코드 모두) 간의 절충이다.
성능 영향이 적은 일부 시스템에서는 함수형 아키텍처를 사용해 유지 보수성을 향상시키는 편이 좋다. 물론 반대로 선택해야 하는 경우도 있다. 즉, 두루 적용되는 해결책은 없다.
6.5.3 코드베이스 크기 증가
함수형 아키텍처는 함수형 코어(불변 코어)와 가변 셸 사이를 명확하게 분리해야 한다. 즉, 코드 복잡도가 낮아지고 유지 보수성이 향상되지만, 초기 코드 작성 비용이 크다.
어떤 코드베이스가 너무 단순하고 비즈니스 관점에서 중요성이 떨어진다고 가정해보자. 이 코드베이스는 초기 투자 비용으로 성과를 내지 못하기 때문에 함수형 아키텍처를 사용하는 것은 무의미하다.
항상 시스템의 복잡도와 중요성을 고려해 함수형 아키텍처를 전략적으로 사용해야 한다.
함수형 방식에서 순수성에 많은 비용이 든다면 과감히 순수성을 따르지 말자.
대부분의 프로젝트에서는 모든 도메인 모델을 불변할 수 없기 때문에 출력 기반 테스트에만 의존할 수 없다. 출력 & 상태 기반을 대부분 사용하고, 필요에 의해서 통신 기반 스타일을 섞어가며 사용하자.
6장의 목표는 모든 테스트를 출력 기반 스타일로 전환하도록 하는 것이 아닌, 가능한 한 많은 테스트를 전환하는 것이기 때문이다.
