
The world's web browsers, servers, and related web applications all talk to each other through HTTP, the Hypertext Transfer Protocl. HTTP is the common language of the modern global Internet.
This chapter is a concise overview of HTTP. You'll see how web applications use HTTP to communicate, and you'll get a rough idea of how HTTP does its job. In particular, we talk about:
•
How web clients and servers communicate
•
Where resources (web content) come from
•
How web transactions work
•
The format of the message used for HTTP communication
•
The underlying TCP network transport
•
The different variations of the HTTP protocol
•
Some of the many HTTP architectural components installed around the Internet
We've got a lot of ground to cover, so let's get started on our tour of HTTP.
1. HTTP: The Internet's Multimedia Courier
Billions of JPEG images, HTML pages, text files, MPEG movies, WAV audio files, Java applets, and more cruise through the Internet each and every day. HTTP moves the bulk of this information quickly, conveniently, and reliably from web servers all around the world to web browsers on people's desktops.
Because HTTP uses reliable data-transmission protocols, it guarantees that your data will not be damaged or scrambled in transit, even when it comes from the other side of the globe. This is good for you as a user, because you can access information without worrying about its intergrity. Reliable transmission is also good for you as Internet application developer, because you don't have to worry about HTTP communications being destroyed, duplicated, or disorted in transit. You can focus on programming the distinguishing details of your application, without worrying about the flaws and foibles of the Internet.
Let's look more closely at how HTTP transports the Web's traffic.
2. Web Clients and Servers
Web content lives on web servers. Web servers speak the HTTP protocol, so they are often called HTTP servers. These HTTP servers store the Internet's data and provide the data when it is requested by HTTP clients. The clients send HTTP request to servers, and servers return the requested data in HTTP responses, as sketched in Figure 1-1. HTTP clients and HTTP servers make up the basic components of the World Wide Web.

Figure 1-1. Web clients and servers
You probably use
3. Resources
3.1. Media Types
3.2. URIs
3.3. URLs
3.4. URNs
4. Transactions
4.1. Methods
4.2. Status Codes
4.3. Web Pages can Consist of Multiple Objects
5. Messages
HTTP message are simple, line-oriented sequences of characters. Because they are plain text, not binary, they are easy for humans to read and write. Figure 1-7 shows the HTTP messages for a simple transaction.
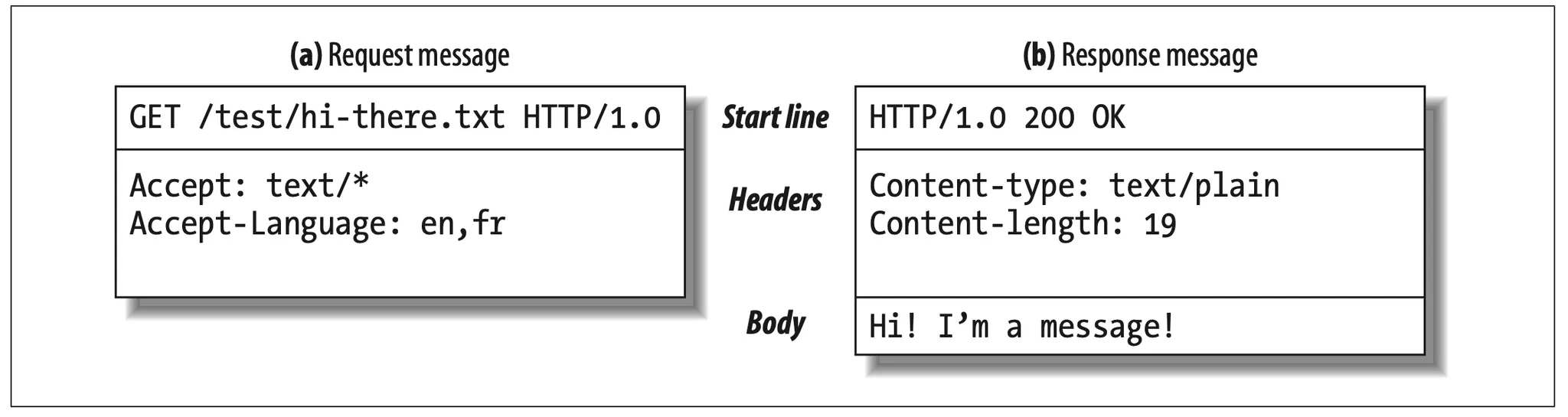
Figure 1-7. HTTP message have a simple, line-oriented text structure
HTTP messages sent from web client to web server are called request messages. Messages from servers to clients are called response messages. There are no other kinds of HTTP messages. The formats of HTTP request and response messages are very similar.
HTTP message consist of three part:
Start line
The first line of the message is the start line, indicating what to do for a request or what happend for a response.
Header fields
Zero or more header fields follow the start line. Each header field consists of a name and a value, separated by a colon(:) for easy parsing. The headers end with a blank line. Adding a header field is as easy as adding another line.
Body
After the blank line is an optional message body containing any kind of data. Request bodies carry data to the web server; response bodies carry data back to the client. Unlike the start lines and headers, which are textual and structed, the body can contain arbitrary binary data (e.g., images, videos, audio tracks, software applications). Of course, the body can also contain text.
5.1. Simple Message Example
Figure 1-8 shows the HTTP messages that might be sent as part of a simple transaction. The browser requests the resource http://www.joes-hardware.com/tools.html.
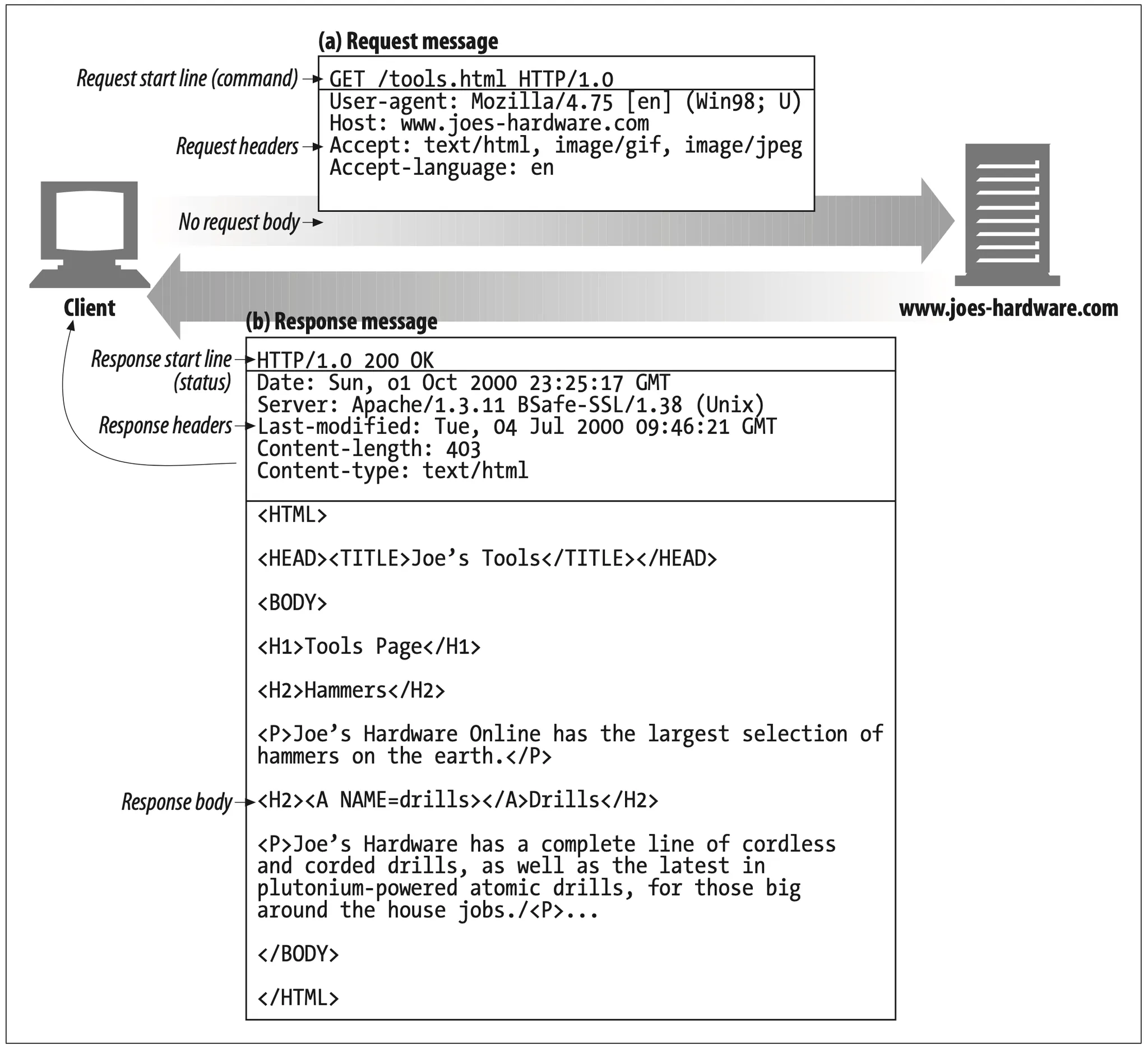
Figure 1-8. Example GET transaction for http://www.joes-hardware.com/tools.html
In Figure 1-8, the browser sends an HTTP requset message. The request has a GET method in the start line, and the local resource is /tools.html. The reqeust indicates it is speaking Version 1.0 of the HTTP protocol. The request message has no body, because no request data is needed to GET a simple document from a server.
The server sends back an HTTP response message. The response contains the HTTP version number(HTTP/1.0), a success status code (200), a descriptive reason phrase (OK), and a block of response header fields, all followed by the response body containing the requested document. The response body length is noted in the Content-Length header, and the document's MIME type is noted in the Content-Type header.
6. Connnections
Now that we've sketched what HTTP's message look like, let's talk for a moment about how message move from place to place, across Transmission Control Protocol(TCP) connections.
6.1. TCP/IP
HTTP is an application layer protocol. HTTP doesn't worry about the nitty-gritty details of network communication; instead, it leaves of details of networking to TCP/IP, the popular reliable Internet transport protocol.
TCP provides:
•
Error-free data transportation
•
In-order delivery (data will always arrive in the order in which it was sent)
•
Unsegmented data stream (can dribble out data in any size at any time)
The Internet itself is based on TCP/IP, a popular layered set of packet-switched network protocols spoken by computes and network devices around the world. TCP/IP hides the peculiarities and foibles of individual networks and hardware, letting computers and networks of any type talk together reliably.
Once a TCP connection is established, messages exchaged between the client and server computers will never be lost, damaged, or received out of order.
In networking terms, the HTTP protocol is layered over TCP. HTTP uses TCP to transport its message data. Likewise, TCP is layered over IP (see Figure 1-9).
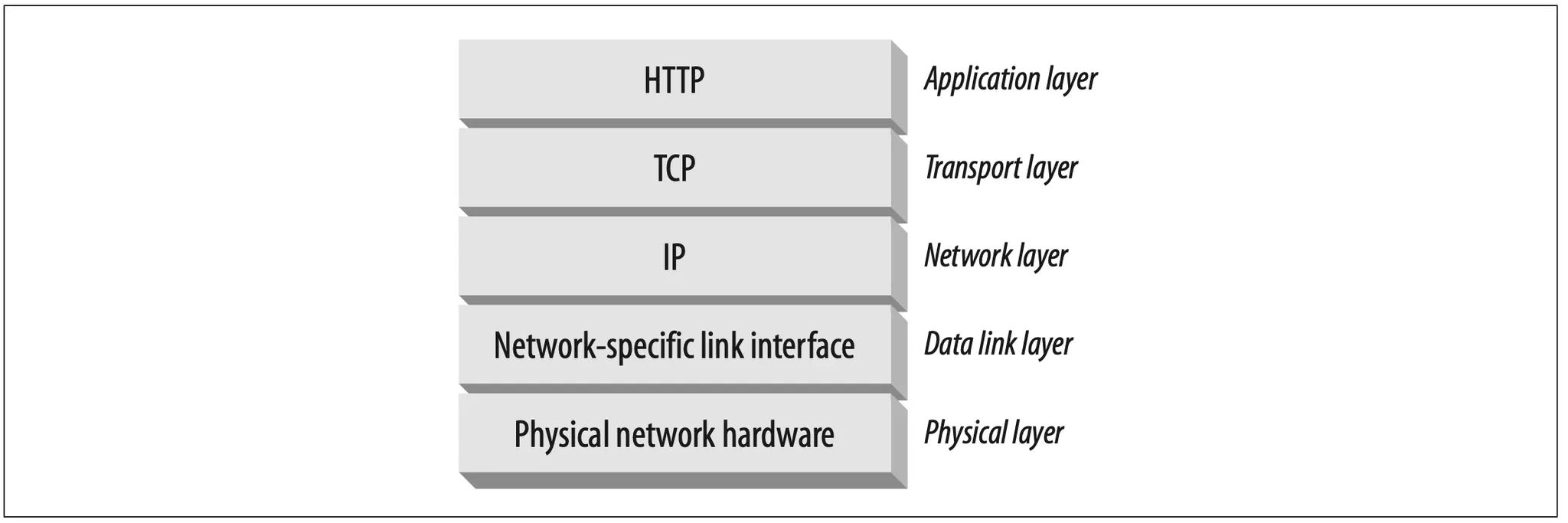
Figure 1-9. HTTP network protocol stack
6.2. Connections, IP Address, and Port Numbers
Before an HTTP client can send a message to a server, it needs to establish a TCP/IP connection between the client and server using Internet protocol (IP) addresses and port numbers.
Setting up a TCP connection is sort of like calling someone at a corporate office. First, you dial the company's phone number. This gets you to the right organization. Then, you dial the specific extension of the person you're trying to reach.
In TCP, you need the IP address of the server computer and the TCP port number associated with the specific software program running on the server.
This is all well and good, but how do you get the IP address and portnumber of the HTTP server in the first place? Why, the URL, of course! We mentioned before that URLs are the address for resources, so naturally enough they can provide us with the IP address for the machine that has the reosource. Let's take a look at a few URLs:
http://207.200.83.29:80/indext.html
http://www.netscape.com:80/index.html
http://www.netscape.com/index.html
The first URL has the machine's IP address, "207.200.83.29", and port number, "80".
The second URL doesn't have a numeric IP address; it has a textual domain name, or hostname ("www.netscape.com"). The hostname is juest a human-friendly alias for an IP address. Hostnames can easily be converted into IP addresses through a facility called the Domain Name Service (DNS), so we're all set here, too. We will talk much more about DNS and URLs in Chapter 2.
The fianl URL has no port number. When the port number is missing from an HTTP URL, you can assume the default value of port 80.
With the IP address and port number, a client can easily communicate via TCP/IP. Figure 1-10 shows how a browser uses HTTP to display a simple HTML resource that resides on a distant server.
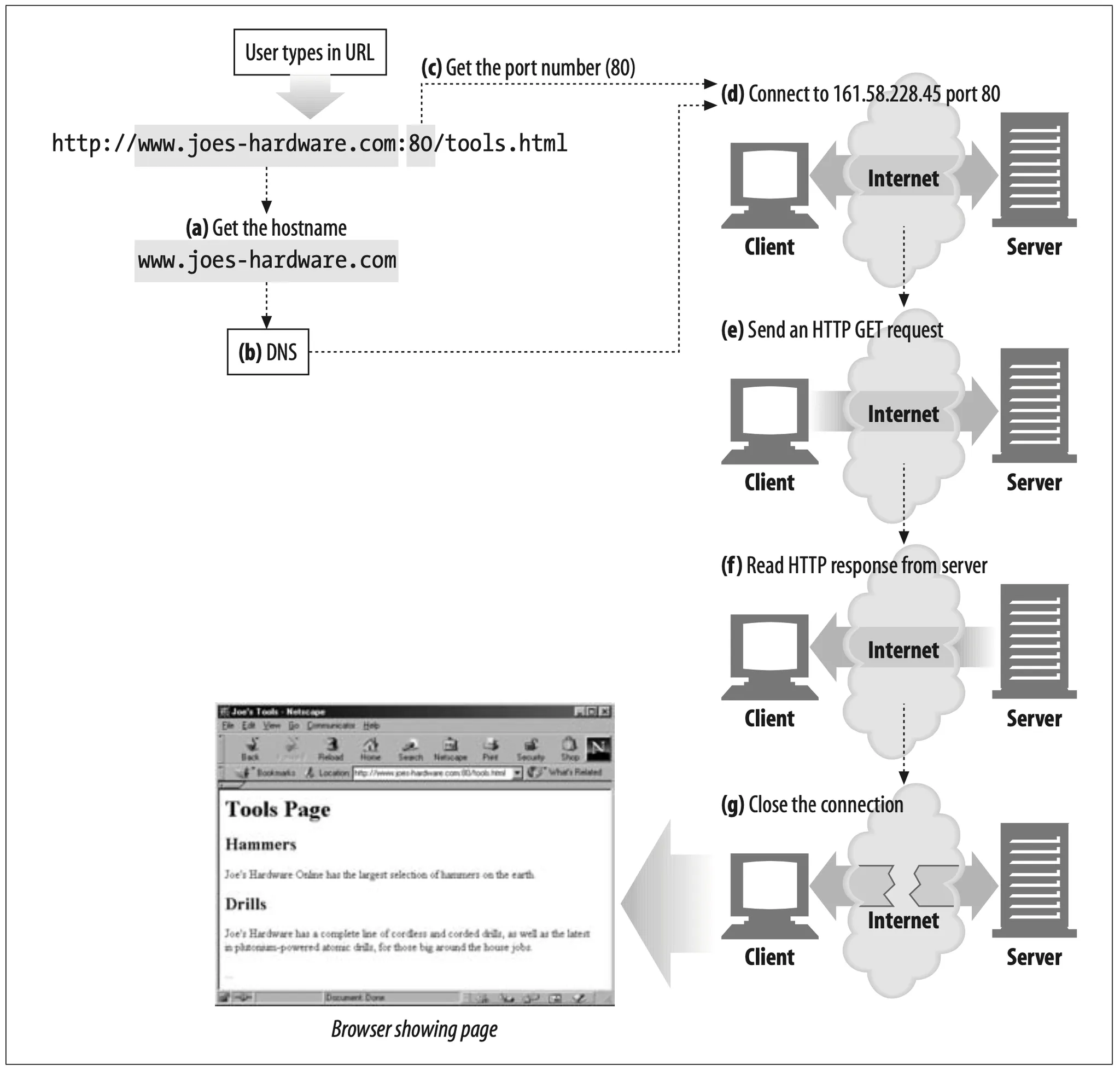
Figure 1-10. Basic browser connection process
Here are the steps:
(a) The browser extracts the server's hostname from the URL.
(b) The browser converts the server's hostname(www.joes-hardware.com) into the server's IP address(161.58.228.45).
(c) The browser extracts the port number (if any) from the URL.
(d) The browser establishes a TCP connection with the web server.
(e) The browser sends an HTTP request message to the server.
(f) The server sends an HTTP response back to the browser.
(g) The connection is closed, and the browser displays the document.
6.3. A Real Example Using Telnet
Skip...
7. Protocol Versions
There are several versions of the HTTP protocol in use today. HTTP applications need to work hard to robustly handle different variations of the HTTP protocl. The versions in use are:
HTTP/0.9
The 1991 prototype version of HTTP is known as HTTP/0.9. This protocol contains many serious design flaws and should be used only to interoperate with legacy clients. HTTP/0.9 supports only the GET method, and it does not support MIME typing of multimedia content, HTTP headers, or version numbers. HTTP/0.9 was originally defined to fetch simple HTML objects. It was soon replaced with HTTP/1.0.
HTTP/1.0
1.0 was the first version of HTTP that was widely depolyed. HTTP/1.0 added version numbers, HTTP headers, additional method, and multimedia object handling. HTTP/1.0 made it practical to support graphically appealing web pages and interactive forms, which helped promote the wide-scale adoption of the World Wide Web. This specification was never well specified. It represented a collection of best practices in a time of rapid commercial and academic evolution of the protocol.
HTTP/1.0+
Many popular web clients and servers rapidly added features to HTTP in the mid-1990s to meet the demands of a rapidly expanding, commercially successful World Wide Web. Many of these features, including long-lasting "keep-alive" connections, virtual hosting support, and proxy connection support, were added to HTTP and became unoficial, de facto standards. This informal, extended version of HTTP is often referred to as HTTP/1.0+.
HTTP/1.1
HTTP/1.1 focused on correcting architectural flaws in the desing of HTTP, specifying semantics, introducing significant performance optimizations, and removing mis-features. HTTP/1.1 also included support for the more sophisticated web applications and deployments that were under way in the late 1990s. HTTP/1.1 is the current version of HTTP.
HTTP-NG (a.k.a. HTTP/2.0)
HTTP-NG is a prototype proposal for an architectural successor to HTTP/1.1 that focuses on significant performance optimizations and a more powerful frame- work for remote execution of server logic. The HTTP-NG research effort con- cluded in 1998, and at the time of this writing, there are no plans to advance this proposal as a replacement for HTTP/1.1. See Chapter 10 for more information.
8. Architectural Components of the Web
In this overview chapter, we've focused on how two web applications (web browsers and web servers) send messages back and forth to implement basic transactions. There are many other web applications that you interact with on the Internet. In this sections, we'll outline several other important applications, including:
Proxies
HTTP intermediaries that sit between clients and servers
Caches
HTTP storehouses that keep copies of popular web pages close to clients
Gateways
Special web servers that connect to other applications
Tunnels
Special proxies that blindly forward HTTP communications
Agents
Semi-intelligent web client that make automated HTTP requests
8.1. Proxies
Let's start by looking at HTTP proxy servers, important building blocks for web security, application integration, and performance optimization.
As shown in Figure 1-11, a proxy sits between a client and a server, receiving all of the client's HTTP requests and relaying the requests to the server(perhaps after modifying the request). These applications act as a proxy for the user, accessing the server on the user's behalf.
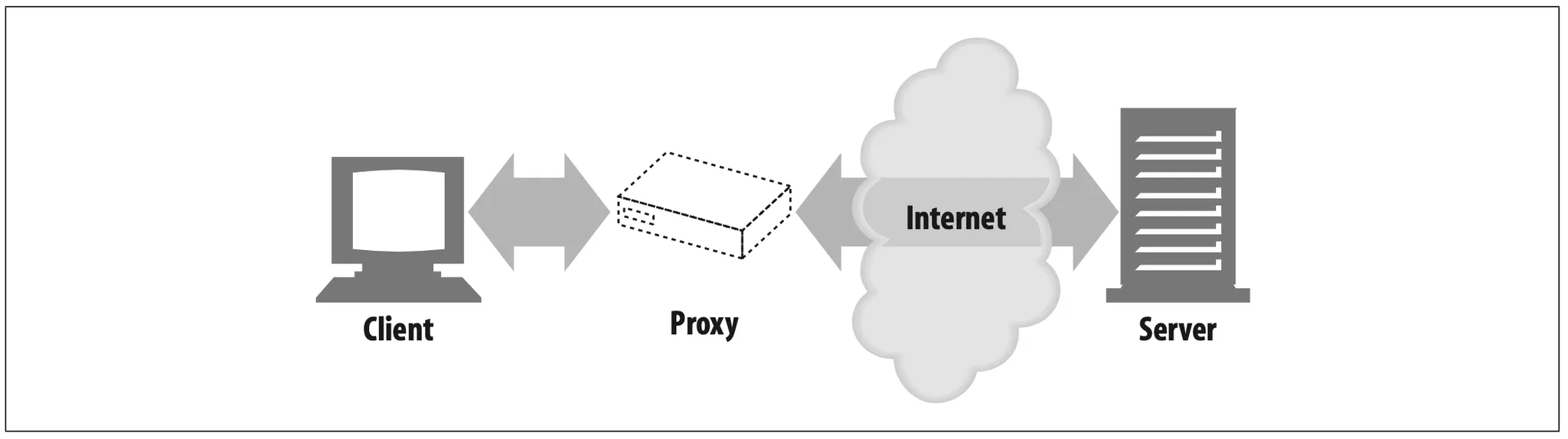
Figure 1-11. Proxies relay traffic between client and server
Proxies are often used for security, acting as trusted intermediaries through which all web traffic flows. Proxies can also filter requests and responses; for example, to detect application viruses in corporate downlaods or to filter adult content away from elementary-school students. We'll talk about proxies in detail in Chapter 6.
8.2. Caches
A web cache or caching proxies is a special type of HTTP proxy server that keeps copies of popular documents that pass through the proxy. The next client requesting the same document can be served from the cache's personal copy (see Figure 1-12).
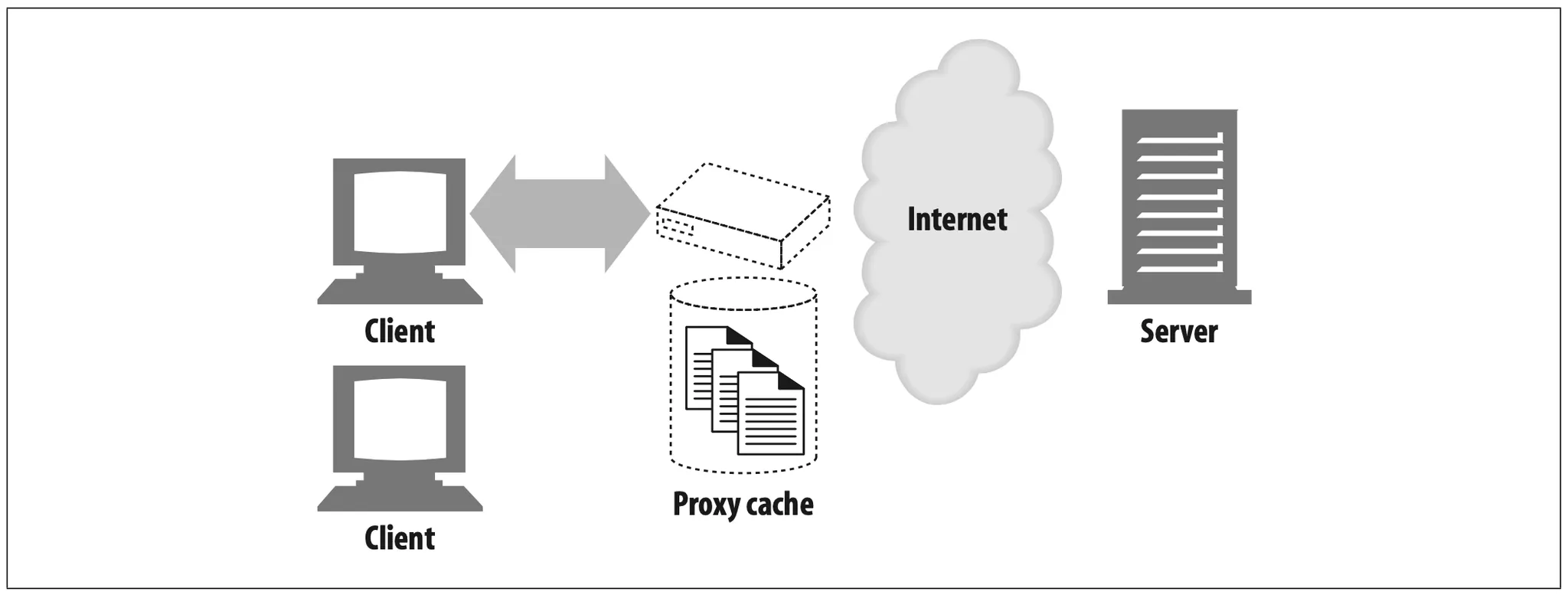
Figure 1-12. Caching proxies keep local copies of popular documents to improve performance
A client may be able to download a document much more quickly from a nearby cache than from a distant web server. HTTP defines many facilities to make caching more effective and to regulate the freshness and privacy of cached content. We cover caching technology in Chapter 7.
8.3. Gateways
Gateways are special servers that act as intermediaries for other servers. They are often used to convert HTTP traffic to another protocol. A gateway always receives requests as if it was the origin server for the resource. The client may not be aware it is communicating with a gateway.
For example, an HTTP/FTP gateway receives requests for FTP URIs via HTTP requests but fetchs the documents using the FTP protocol (see Figure 1-13). The resulting document is packed into an HTTP message and sent to the client. We discuss gateways in Chapter 8.
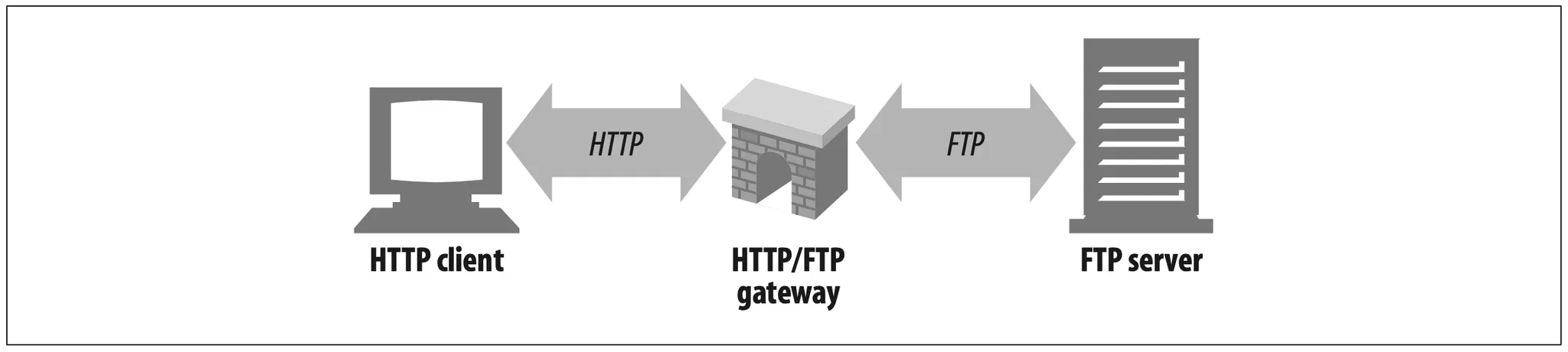
Figure 1-13. HTTP/FTP gateway
8.4. Tunnels
Tunnels are HTTP applications that, after setup, blindly relay raw data between two connections. HTTP tunnels are often used to transport non-HTTP data over one or more HTTP connections, without looking at the data.
One popular use of HTTP tunnels is to carry encrypted Secure Sockets Layer (SSL) traffic through an HTTP connection, allowing SSL traffic through corporate firewalls that permit only web traffic. As sketched in Figure 1-14, an HTTP/SSL tunnel receives an HTTP request to establish an outgoing connection to a destination address and port, then proceeds to tunnel the encrypted SSL traffic over HTTP channel so that it can be blindly relayed to the destination server.
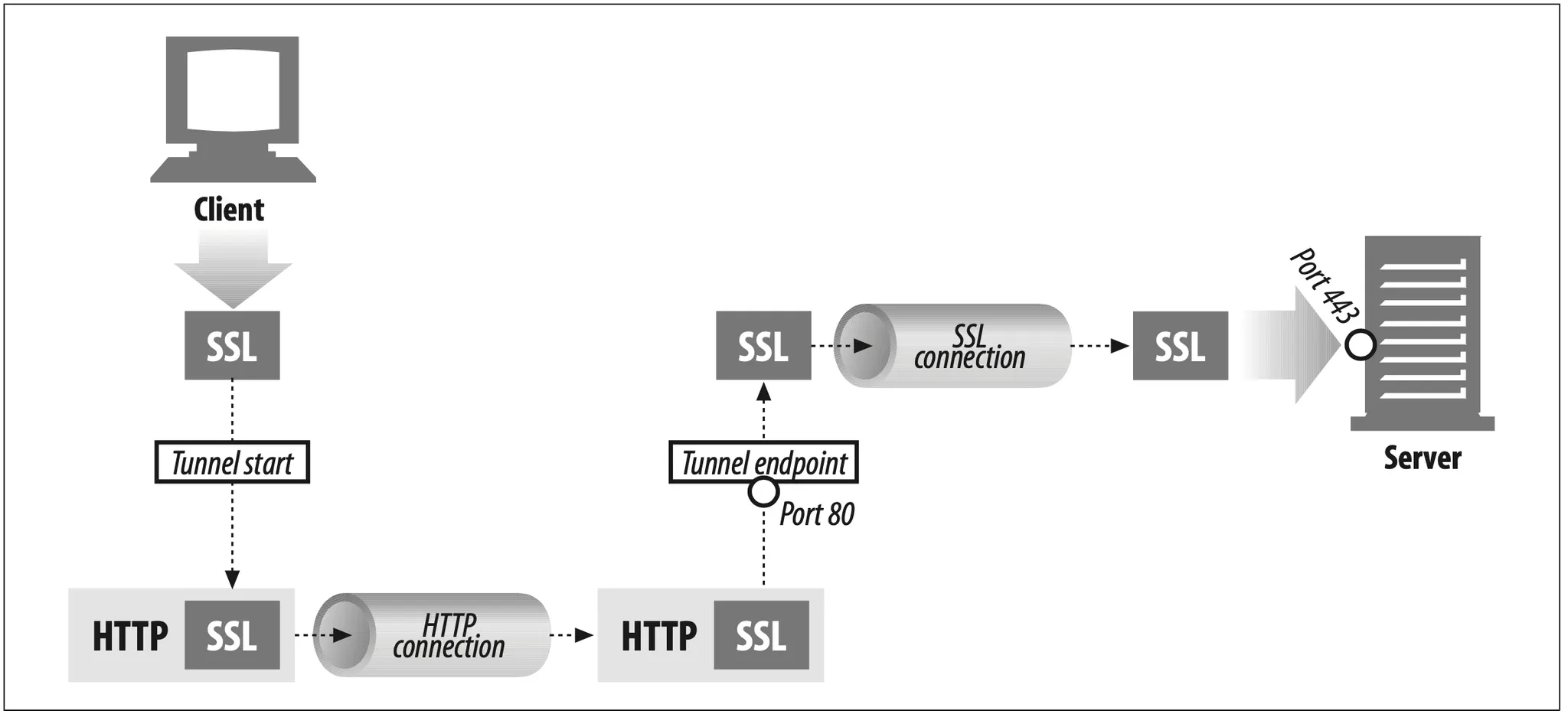
Figure 1-14. Tunnels forward data across non-HTTP networks (HTTP/SSL tunnel shown)
8.5. Agents
User agents (or just agents) are client programs that make HTTP requests on the user's behalf. Any application that issues web requests is an HTTP agent. So far, we've talked about only one kind of HTTP agent: web browsers. But there are many other kinds of user agents.
For example, there are machine-automated user agents that autonomously wander the Web, issuing HTTP transactions and fetching content, without human supervision. These automated agents often have colorful names, such as "spiders" or "webrobos" (see Figure 1-15). Spiders wander the Web to build useful archives of web content, such as a search engine;s database or a product catalog for a comparison shopping robot. See Chapter 9 for more information.
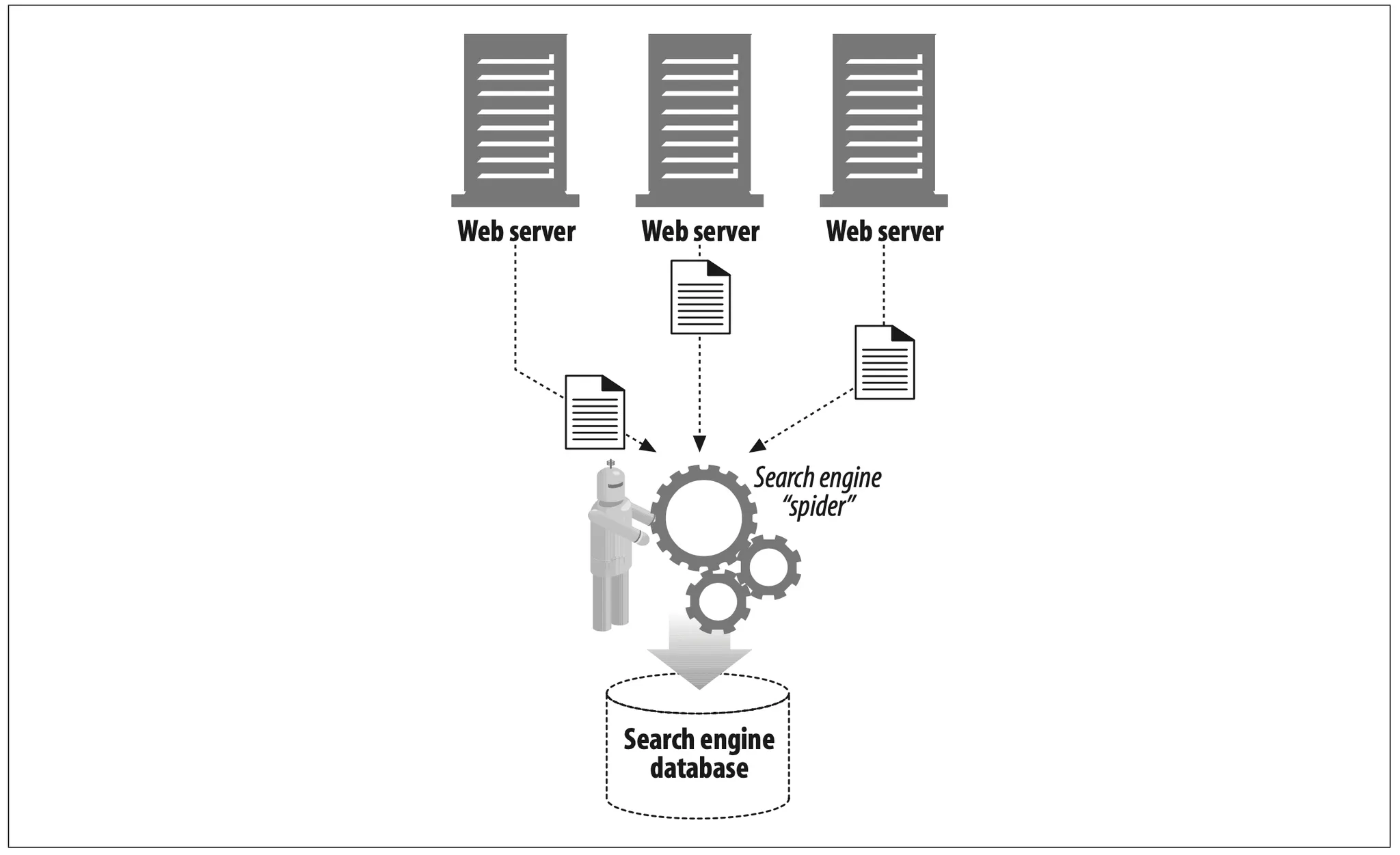
Figure 1-15. Automated search engin "spiders" are agents, fetching web pages around the world
9. The End of the Beginning
Skip...
10. For More Information
Skip...
