
4.1. Lambdas
Lambdas produce compact code that't easier to understand.
•
A lambda (also called a function literal) is a low-ceremony function
•
It has no name, requires a minimal amount of code to create, and you can insert it directly into other code.
•
The lambda is the code within the curly braces used in the initialization of result.
•
The parameter list is separated from the function body by an arrow ->.
•
The function body can be one or more expressions. The final expression becomes the return value of the lambda.
•
BasicLambda.kt shows the full lambda syntax, but this can often be simplified.
•
We typically create and use a lambda in place, which means Kotlin can usually infer type information.
•
If there's only a single parameter, Kotlin generates the name it for that parameter:
•
If the lambda is the only function argument, or the last argument, you can remove the parentheses around the curly braces, producing cleaner syntax:
•
If the function takes more than one argument, all except the last lambda argument must be in parentheses.
•
Here's the syntax for a lambda with more than one parameter
•
If you aren't using a particular argument, you can ignore it using an underscore to eliminate compiler warnings about unused identifiers:
•
Note that Underscore.kt can be rewritten using list.indices:
•
Lambdas can have zero parameters, in which case you can leave the arrow for emphasis, but the Kotlin style guide recommends omitting the arrow:
You can use a lambda anywhere you use a regular function, but if the lambda becomes too complex it's often better to define a named function, for clarity, even if you're only going to use it once.
4.2 The Importance of Lambdas
Lambdas may seem like syntax sugar, but they provide important power to your programming.
•
Code often manipulates the contents of a collection, and typically repeats these manipulations with minor modifications.
•
The standard library function filter() takes a predicate specifying the elements you want to preserve, and this predicate can be a lambda:
•
Notice that filter() handles the iteration that would otherwise require handwritten code.
•
Although managing the iteration yourself might not seem like much effort, it's one more error-prone detail and one more place to make a mistake.
•
Because they're so "obvious," such mistakes are particularly hard to find.
This is one of the hallmarks of functional programming, of which map() and filter() are examples. Functional programming solves problems in small steps. The functions often do things that seem trivial—it's not that hard to write your own code rather than using map() and filter(). However, once you have a collection of these small, debugged solutions, you can easily combine them without debugging at every level. This allows you to create more robust code, more quickly.
•
You can store a lambda in a var or val. This allows reuse of that lambda's logic, by passing it as an argument to different functions:
•
When we define isEven we must specify the parameter type because there is no context for the type inferencer.
•
Another important quality of lambdas is the ability to refer to elements outside their scope.
•
When a function "closes over" or "captures" the elements in its environment, we call it a closure.
•
Unfortunately, some languages conflate the term "closure" with the idea of a lambda.
•
The two concepts are completely distinct: you can have lambdas without closures, and closures without lambdas.
•
When a language supports closures, it "just works" the way you expect:
•
Here, the lambda "captures" the val divider that is defined outside the lambda.
The lambda not only reads captured element, it can also modify them:
•
The forEach() library function applies the specified action to each element of the collection.
•
Although you can capture the mutable variable sum as in Closures2.kt, you can usually change your code and avoid modifying the state of your environment:
•
An ordinary function can also close over surrounding elements:
•
useX() captures and modifies x from its surroundings.
4.3 Operations on Collections
An essential aspect of functional language is the ability to easily perform batch operations on collections of objects.
•
Most functional languages provide powerful support for working with collections, and Kotlin is no exception.
•
This atom shows additional operations available for Lists and other collections.
•
We start by looking at various ways to manufacture Lists. Here, we initialize Lists using lambdas:
•
MutableLists can be initialized in the same way.
•
Note that List() and MutableList() are not constructors, but functions. Their names intentionally begin with an upper-case letter to make them look like constructors.
•
Many collection functions take a predicate and test it against the elements of a collection, some of which we've already seen:
◦
filter() produces a list containing all elements matching the given predicate.
◦
any() returns true if at least one element matches the predicate.
◦
all() checks whether all elements match the predicate.
◦
none() checks that no elements match the predicate.
◦
find() and firstOrNull() both return the first element matching the predicate, or null if no such element was found.
◦
lastOrNull() returns the last element matching the predicate, or null.
◦
count() returns the number of elements matching the predicate.
•
filter() and count() apply the predicate against each element, while any() or find() stop when the first matching result is found.
•
Sometimes you may be interested in the remaining group—the elements that don't satisfy the predicate.
•
filterNot() produces this remaining group, but partition() can be more useful because it simultaneously produces both lists:
filterNotNull() produces a new List with the nulls removed:
In Lists, we saw functions such as sum() or sorted() applied to a list of comparable elements. These functions can't be called on lists of non-summable or non-comparable elements, but they have counterparts named sumBy() and sortedBy(). You pass a function (often a lambda) as an argument, which specifies the attribute to use for the operation:
Note that we have two functions sumBy() and sumByDouble() to sum integer and double values, respectively. sorted() and sortedBy()sort the collection in ascending order, while sortedDescending() and sortedByDescending() sort the collection in descending order.
minByOrNull returns a minimum value based on a given criteria or null if the list is empty.
take() and drop() produce or remove (respectively) the first element, while takeLast() and dropLast() produce or remove the last element. These have counterparts that accept a predicate specifying the elements to take or drop:
Operations like those you've seen for Lists are also available for Sets:
maxByOrNull() returns null if a collection is empty, so its result is nullable.
Note that filter() and map(), when applied to a Set, return their results in a List.
4.4 Member Reference
You can pass a member reference as a function argument.
Member references—for functions, properties and constructors—can replace trivial lambdas that simply call the corresponding function, property or constructor.
A member reference uses a double colon to separate the class name from the function or property. Here, Message::isRead is a member reference:
To filter for unread messages, we use the library function filterNot(), which takes a predicate. In our case, the predicate indicates whether a message is already read. We could pass a lambda, but instead we pass the property reference Message::isRead.
Property references are useful when specifying a non-trivial sort order:
The library function sortedWith() sorts a list using a comparator, which is an object used to compare two elements. The library function compareBy() builds a comparator based on its parameters, which are a list of predicates. Using compareBy() with a single argument is equivalent to calling sortedBy().
Function References
Suppose you want to check whether a List contains any important messages, not just unread messages. You might have a number of complicated criteria to decide what "important" means. You can put this logic into a lambda, but that lambda could easily become large and complex. The code is more understandable if you extract it into a separate function. In Kotlin you can't pass a function where a function type is expected, but you can pass a reference to that function:
This new Message class adds an attachments property, and the extension function Message.isImportant() uses this information. In the call to messages.any(), we create a reference to an extension function—references are not limited to member functions.
If you have a top-level function taking Message as its only parameter, you can pass it as a reference. When you create a reference to a top-level function, there's no class name, so it's written ::function:
Constructor References
You can create a reference to a constructor using the class name.
Here, names.mapIndexed() takes the constructor reference ::Student:
mapIndexed() was introduced in Lambdas. It turns each element in names into the index of that element along with the element. In the definition of students, these are explicitly mapped into the constructor, but the identical effect is achieved with names.mapIndexed(::Student). Thus, function and constructor reference can eliminate specifying a long list of parameters that are simply passed into a lambda. Function and constructor references are often more readable that lambdas.
Extension Function References
To produce a reference to an extension function, prefix the reference with the name of the extended type:
In goInt(), g is a function that expects an Int argument and produces an Int. In goFrog(), g expects a Frog and produces a String.
4.5 Higher-Order Functions
A language supports higher-order functions if its functions can accept other functions as arguments and produce functions as return values.
Higher-Order functions are an essential part of functional programming languages. In previous atoms, we've seen higher-order functions such as filter(), map(), and any().
You can store a lambda in a reference. Let's look at the type of this storage:
(Int) → Boolean is the function type: it starts with parentheses surrounding zero or more parameter types, then an arrow (→), followed by the return type.
(Arg1Type, Arg2Type... ArgNType) -> ReturnType
Kotlin
복사
The syntax for calling a function through a reference is identical to an ordinary function call:
When a function accepts a function parameter, you can either pass it a function reference or a lambda. Consider how you might define any() from the standard library:
•
[1] any() should be usable with Lists of different types so we define it as an extension to the generic List<T>.
•
[2] The predicate function is callable with a parameter of type T so we can apply it to the List elements.
•
[3] Applying predicate() tells whether that element fits our criteria.
•
The type of the lambda differs: it's Int in [4] and String in [5].
•
[6] A member reference is another way to pass a function reference.
repeat() from the standard library takes a function as its second parameter. It repeats an action an Int number of times:
Consider how repeat() might be defined:
•
[1] repeat() takes a parameter action of the function type (Int) -> Unit.
•
[2] When action() is called, it is passed the current repetition index.
•
[3] When calling repeat(), you access the repetition index using it inside the lambda.
A function return type can be nullable:
toIntOrNull() might return null, so transform() accepts a String and returns a nullable Int?. mapNotNull() converts each element in a List into a nullable value and removes all nulls from the result. It has the same effect as first calling map(), then applying filterNotNull() to the resulting list.
Note the difference between making the return type nullable versus making the whole function type nullable:
Before calling the function stored in mightBeNull, we must ensure that the function reference itself is not null.
4.6 Manipulating Lists
Zipping and flattening are two common operation that manipulate Lists.
Zipping
zip() combines two Lists by mimicking the behavior of the zipper on your jacket, pairing adjacent List elements:
•
[1] Zipping left with right results in a List of Pairs, combining each element in left with its corresponding element in right.
•
[2] You can also zip() a List with a range.
•
[3] The range 10..100 is much larger than right, but the zipping process stops when one sequence runs out.
zip() can also perform an operation on each Pair it creates:
names.zip(ids) { ... } produces a sequence of name-id Pairs, and applies the lambda to each Pair. The result is a List of initialized Person objects.
To zip two adjacent elements from a single List, use zipWithNext():
The second call to zipWithNext() performs an additional operation after zipping.
Flattening
flatten() takes a List containing elements that are themselves Lists—a List of Lists—and flattens it into a List of single elements:
flatten() helps us understand another important operation on collections: flatMap(). Let's produce all possible Pairs of a range of Ints:
The lambda in each case is identical: every intRange element is combined with every intRange element to produce all possible a to bPairs. But in [1], map() helpfully preserves the extra information that we have produced three Lists, one for each element in intRange. There are situations where this extra information is essential, but here we don't want it—we just need a single flat List of all combinations, with no additional structure.
There are two options. [2] shows the application of the flatten() function to remove this additional structure and flatten the result into a single List, which is an acceptable approach. However, this is such a common task that Kotlin provides a combined operation called flatMap(), which performs both map() and flatten() with a single call. [3] shows flatMap() in action. You'll find flatMap() in most languages that support functional programming.
Here's a second example of flatMap():
We'd like a List of authors. map() produces a List of List of authors, which isn't very convenient. flatten() takes that and produces a simple List. flatMap() produces the same results in a single step.
Here, we use map() and flatMap() to combine the enums Suit and Rank, producing a deck of Cards:
In the initialization of deck, the inner Rank.values().map produces four Lists, one for each Suit, so we use flatMap() on the outer loop to produce a List<Card> for deck.
4.7 Building Maps
Maps are extremely useful programming tools, and there are numerous ways to construct them.
To create a repeatable set of data, we use the technique shown in Manipulating Lists, where two Lists are zipped and the result is used in a lambda to call a constructor, producing a List<Person>:
A Map uses keys to provide fast access to its values. By building a Map with age as the key, we can quickly look up groups of people by age. The library function groupBy() is one way to create such a Map:
groupBy()'s parameter produces a Map where each key connects to a List of elements. Here, all people of the same age are selected by the age key.
You can produce the same groups using the filter() function, but groupBy() is preferable because it only performs the grouping one. With filter() you must repeat the grouping for each new key:
Here, groupBy() groups people() by their first character, selected by first(). We can also use filter() to produce the same result by repeating the lambda code for each character.
If you only need two groups, the partition() function is more direct because it divides the contents into two lists based on a predicate. groupBy() is appropriate when you need more that two resulting groups.
associateWith() allows you to take a list of keys and build a Map by associating each these keys with a value created by its parameter(here, the lambda):
associateBy() reverses the order of association produced by associateWith()—the selector (the lambda in the following example) becomes the key:
associateBy() must be used with a unique selection key and returns a Map that pairs each unique key to the single element selected by that key.
If multiple values are selected by the predicate, as in ages, only the last one appears in the generated Map.
getOrElse() tries to look up a value in a Map. Its associated lambda computes a default value when a key is not present. Because it's a lambda, we compute the default key only when necessary:
getOrPut() works on a MutableMap. If a key is present it simply returns the associated value. If the key isn't found, it computes the value, puts it into the map and returns that value.
Many Map operations duplicate ones in List. For example, you can filter() or map() the contents of a Map. You can filter keys and values separately:
All three functions filter(), filterKeys() and filterValues() produce a new map containing only the elements that satisfy the predicate. filterKeys() applies its predicate to the keys, and filterValues() applies its predicate to the values.
Applying Operations to Maps
To map() a Map sounds like a tautology, like saying "salt is salty." The word map represents two distinct ideas:
•
Transforming a collection
•
The key-value data structure
In many programming languages, the word map is used for both concepts. For clarity, we say transform a map when applying map() to a Map.
Here we demonstrate map(), mapKeys() and mapValues():
•
[1] Here, map() takes a predicate with a Map.Entry argument. We access its contents as it.key and it.value.
•
•
[3] If a parameter isn't used, an underscore (_) avoids compiler complaints. mapKeys() and mapValues() return a new map, with all keys or values transformed accordingly.
•
[4] map() returns a list of pairs, so to produce a Map we use the explicit conversion toMap().
Functions like any() and all() can also be applied to Maps:
any() checks whether any of the entries in a Map satisfy the given predicate, while all() is true only if all entries in the Map satisfy the predicate.
maxByOrNull() finds the maximum entry based on the given criteria. There may not be a maximum entry, so the result is nullable.
4.8 Sequences
A Kotlin Sequence is like a List, but you can only iterate through a Sequence—you cannot index into a Sequence. This restriction produces very efficient chained operations.
Kotlin Sequences are termed streams in other functional languages. Kotlin had to choose a different name to maintain interoperability with the Java 8 Stream library.
Operations on Lists are performed eagerly—they always happen right away. When chaining List operations, the first result must be produced before the next operation. Here, each filter(), map() and any() operation is applied to every element in list:
Eager evaluation is intuitive and straightforward, but can be suboptimal. In EagerEvaluation.kt, it would make more sense to stop after encountering the first element that satisfies the any(). For a long sequence, this optimization might be much faster than evaluating every element and then searching for a single match.
Eager evaluation is sometimes called horizontal evaluation:
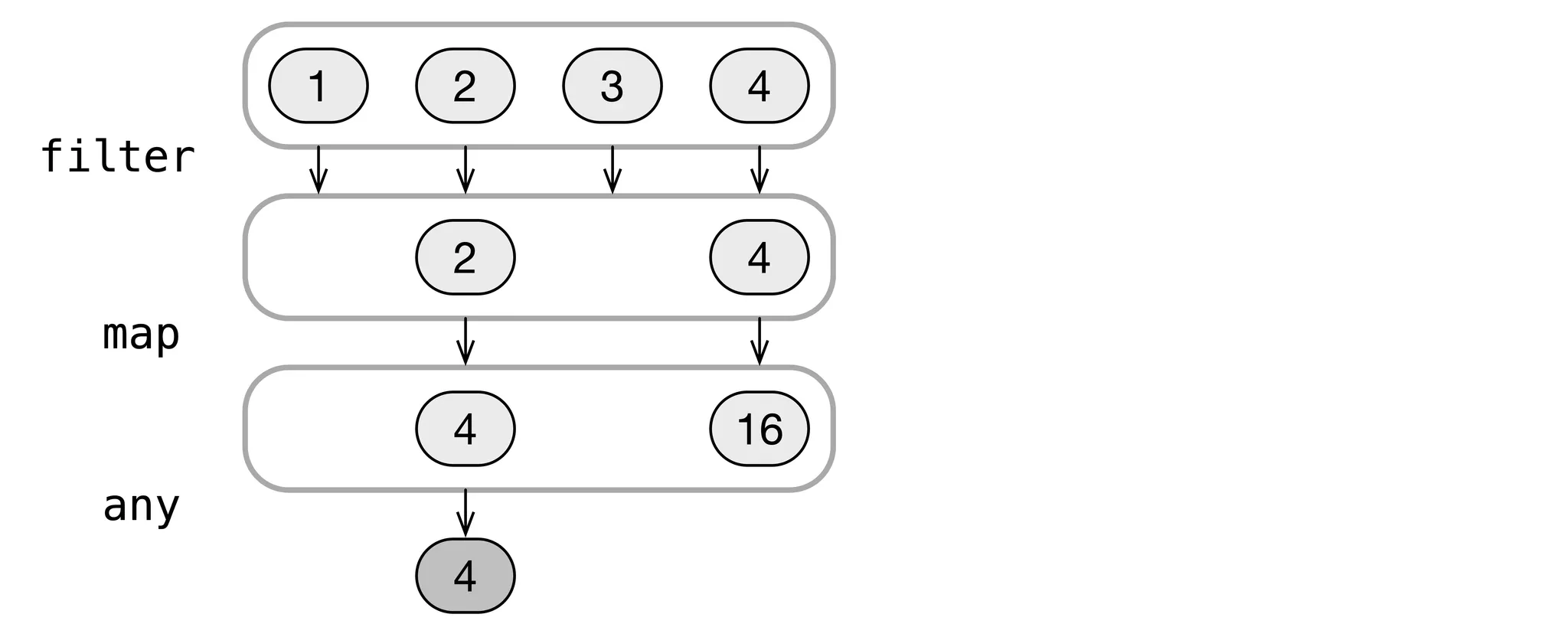
The first line contains the initial list contents. Each following line shows the results from the previous operation. Before the next operation is performed, all elements on the current horizontal level are precessed.
The alternative to eager evaluation is lazy evaluation: a result is computed only when needed. Performing lazy operations on sequences is sometimes called vertical evaluation:
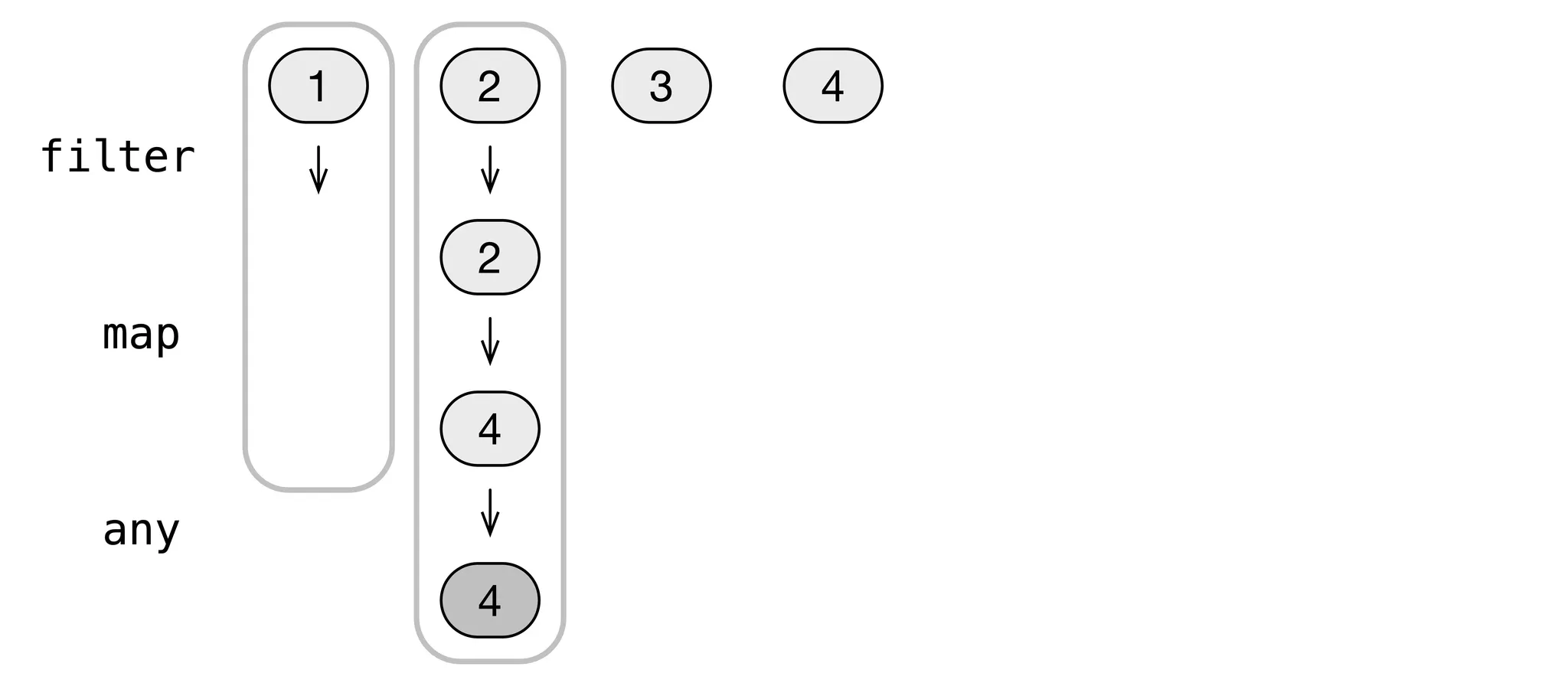
With lazy evaluation, an operation is performed on an element only when that element's associated result is requested. If the final result of a calculation is found before processing the last element, no further elements are processed.
Converting Lists to Sequences using asSequence() enables lazy evaluation. All List operations except indexing are also available for Sequences, so you can usually make this single change and gain the benefits of lazy evaluation.
The following example shows the above diagrams converted into code. We perform the identical of operations, first on a List, then on a Sequence. The output shows where each operation is called:
The only difference between the two approaches is the addition of the asSequence() call, but more elements are processed for the List code than the Sequence code.
Calling either filter() or map() on a Sequence produces another Sequence. Nothing happens until you ask for a result from a calculation. Instead, the new Sequence stores all information about postponed operations and will perform those operations only when needed:
Converting r to a String does not produce the results we want, but just the identifier for the object (including the @ address of the object in memory, which we remove using the standard library substringBefore()). The TransformingSequence just holds the operations but does not perform them.
There are two categories of Sequence operations: intermediate and terminal. Intermediate operations return another Sequence as a result. filter() and map() are intermediate operations. Terminal operations return a non-Sequence. In the previous examples, any() is a terminal operation because it takes a Sequence and returns a Boolean. In the following example, toList() is terminal because it converts the Sequence to a List, running all stored operations in the process:
Because a Sequence stores the operations, it can call those operations in any order, resulting in lazy evaluation.
The following example uses the standard library function generateSequence() to produce an infinite sequence of natural numbers. The first argument is the initial element in the sequence, followed by a lambda defining how the next element is calculated from the previous element:
Collections are a known size, discoverable through their size property. Sequences are treated as if they are infinite. Here, we decide how many elements we want using take(), followed by a terminal operation (toList() or sum()).
There's an overloaded version of generateSequence() that doesn't require the first parameter, only a lambda that returns the next element in the Sequence. When there are no more elements, it returns null. The following example generates a Sequence until the "termination flag" XXX appears in its input:
removeAt(0) removes and produces the zeroeth element from the List. takeIf() returns the receiver (the String produced by removeAt(0)) if it satisfies the given predicate, and null if the predicate fails (when the String is "XXX").
You can only iterate once through a Sequence. Further attempts produce an exception. To make multiple passes through a Sequence, first convert it to some type of Collection.
Here's an implementation for takeIf(), defined using a generic T so it can work with any type of argument:
Here, generateSequence() and takeIf() produce a decreasing sequence of numbers:
An ordinary if expression can always be used instead of takeIf(), but introducing an extra identifier can make the if expression clumsy. The takeIf() version is more functional, especially if it's used as a part of a chain of calls.
4.9 Local Functions
You can define functions anywhere—even inside other functions.
Named functions defined within other functions are called local functions. Local functions reduce by extracting repetitive code. At the same time, they are only visible the surrounding function, so they don't "pollute your namespace." Here, even though log() is defined just like any other function, it's nested inside main():
Local functions are closures: they capture vars or vals from the surrounding environment that would otherwise have to be passed as additional parameters. This way, you don't repeatedly pass logMsg into log().
You can create local extension functions:
exclaim() is available only inside main().
Here is a demonstrate class and example values for use in this atom:
You can refer to a local function using a function reference:
interesting() is only used once, so we might be inclined to define it as a lambda. As you will see later in this atom, the return expressions within interesting() complicate the task of turning it into a lambda. We can avoid this complication with an anonymous function. Like local functions, anonymous functions are defined within other functions—however, an anonymous function has no name. Anonymous functions are conceptually similar to lambdas but use the fun keyword. Here's LocalFunctionReference.kt rewritten using anonymous function:
•
[1] An anonymous function looks like a regular function without a function name. Here, the anonymous functions is passed as an argument to session.any().
If a lambda becomes too complicated and hard to read, replace it with a local function or an anonymous function.
Labels
Here, forEach() acts upon a lambda containing a return:
A return expression exits a function defined using fun (that is, not a lambda). In line [1] this means returning from main(). Line [2] is never called and you see no output.
To return only from a lambda, and not from the surrounding function, use a labeled return:
Here, the label is the name of the function that called the lambda. The labeled return expression return@forEach tells it to return only to the name forEach.
You can create a label by preceding the lambda with label@, where label can be any name:
•
[1] this lambda is labeled tag.
•
[2] return@tag returns from the lambda, not from main().
Let's replace the anonymous function in InterestingSessions.kt with a lambda.
We must return to a label so it exits only the lambda and not main().
Manipulating Local Functions
You can store a lambda or an anonymous function in a var or val, then use that identifier to call the function. To store a local function, use a function reference (see Member References).
In the following example, first() creates an anonymous function, second() uses a lambda, and third() returns a reference to a local function. fourth() achieves the same effect as third() but uses a more compact expression body. fifth() produces the same effect using a lambda:
main() first verifies that calling each function does indeed return a function reference of the expected type. Each funRef is then called with an appropriate argument. Finally, each function is called and then the returned function reference is immediately called by adding an appropriate argument list. For example, calling first() returns a function, so we call that function by appending the argument list (42).
4.10 Folding Lists
fold() combines all elements of a list, in order, to generate a single result.
A common exercise is to implement operations such as sum() or reverse() using fold(). Here, fold() sums a sequence:
fold() takes the initial value (its argument, 0 in this case) and successively applies the operation (expressed here as a lambda) to combine the current accumulated value with each element. fold() first adds 0 (the initial value) and 1 to get 1. That becomes the sum, which is then added to the 10 to get 11, which becomes the new sum. The operation is repeated for two more elements:100 and 1000. This produces 111 and 1111. The fold() will stop when there is nothing else in the list, returning the final sum of 1111. Of course, fold() doesn't really know it's doing a "sum"—choice of identifier name was ours, to make it easier to understand.
To illuminate the steps in a fold(), here's SumViaFold.kt using an ordinary for loop:
fold() accumulates values by successively applying operation to combine the current element with the accumulator value.
Although fold() is an important concept and the only way to accumulate values in pure functional languages, you may sometimes still use an ordinary for loop in Kotlin.
foldRight() processes elements starting from right to left, as opposed to fold() which passes the elements from left to right. This example demonstrates the difference:
fold() first applies the operation to a, as we can see in (*) + a, while foldRight() first processes the right-hand element d, and processes a last.
fold() and foldRight() take an explicit accumulator value as the first argument. Sometimes the first element can act as an initial value. reduce() and reduceRight() behave like fold() and foldRight() but use the first and last element, respectively, as the initial value:
4.11 Recursion
Recursion is the programming technique of calling a function within that same function. Tail recursion is an optimization that can be explicitly applied to some recursive functions.
A recursive function uses the result of the previous recursive call. Factorials are a common example—factorial(n) multiplies all numbers from 1 to n, and can be defined like this:
•
factorial(1) is 1
•
factorial(n) is n * factorial(n - 1)
factorial() is recursive because it uses the result from the same function applied to its modified argument. Here's a recursive implementation of factorial():
While this is easy to read, it's expensive. When calling a function, the information about that function and its arguments are stored in a call stack. You see the call stack when an exception is thrown and Kotlin displays the stack trace:
If you uncomment the line containing the exception, you'll see the following:

The stack trace displays the state of the call stack at the moment the exception is thrown. For CallStack.kt, the call stack consists of only three functions:

We start in main(), which calls fail(). The fail() call is added to the call stack along with its arguments. Next, fail() calls illegalState(), which is also added to the call stack.
When you call a recursive function, each recursive invocation adds a frame to the call stack. This can easily produce a StackOverflowError, which means that your call stack became too large and exhausted the available memory.
Programmers commonly cause StackOverflowErrors by forgetting to terminate the chain of recursive calls—this is infinite recursion:
If you uncomment the line in main(), you'll see a stacktrace with many duplicate calls:

The recursive function keeps calling itself (with a different argument each time), and fills up the call stack:

Infinite recursion always ends with a StackOverflowError, but you can produce the same result without infinite recursion, simply by making enough recursive function calls. For example, let's sum the integers up to a given number, recursively defining sum(n) as n + sum(n - 1):
This recursion quickly becomes expensive. If you uncomment line [1], you'll discover that it takes far too long to complete, and all those recursive calls overflow the stack. If sum(100_000) still works on your machine, try a bigger number.
Calling sum(100_000) causes a StackOverflowError by adding 100_000 sum() function calls to the call stack. For comparison, line [2]uses the sum() library function to add the numbers within the range, and this does not fail.
To avoid a StackOverflowError, you can use an iterative solution instead of recursion:
There's no risk of a StackOverflowError because we only make a single sum() call and the result is calculated in a for loop. Although the iterative solution is straightforward, it must use the mutable state variable accumulator to store the changing value, and functional programming attempts to avoid mutation.
To prevent call stack overflows, functional languages (including Kotlin) use a technique called tail recursion. The goal of tail recursion is to reduce the size of the call stack. In the sum() example, the call stack becomes a single function call, just as it did in Iteration.kt:
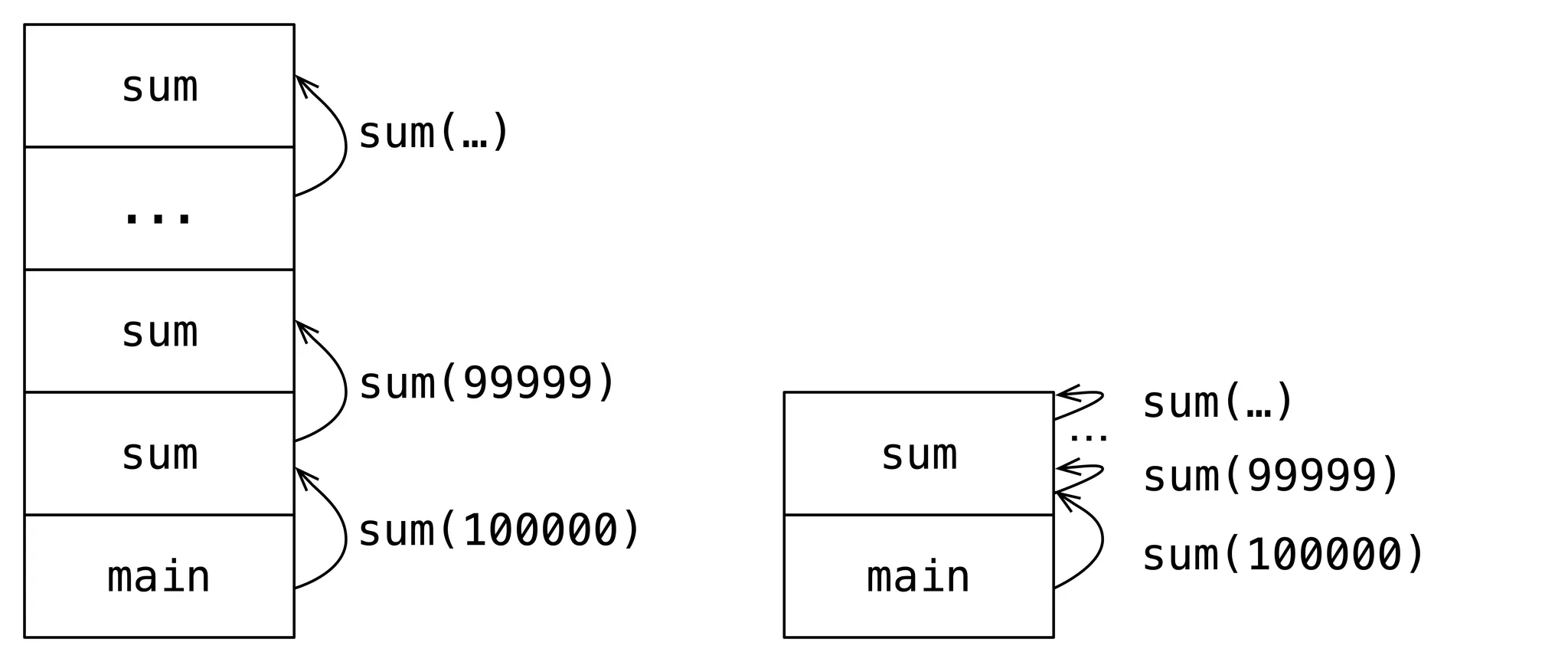
To produce tail recursion, use the tailrec keyword. Under the right conditions, this converts recursive calls into iteration, eliminating call-stack overhead. This is a compiler optimization, but it won't work for just any recursive call.
To use tailrec successfully, recursion must be the final operation, which means there can be no extra calculations on the result of the recursive call before it is returned. For example, if we simply put tailrec before the fun for sum() in RecursionLimits.kt, Kotlin produces the following warning messages:
•
A function is marked as tail-recursive but no tail calls are found
•
Recursive call is not a tail call
The problem is that n is combined with the result of the recursive sum() call before returning that result. For tailrec to be successful, the result of the recursive call must be returned without doing anything to it during the return. This often requires some work in rearranging the function. For sum(), a successful tailrec looks like this:
By including the accumulator parameter, the addition happens during the recursive call and you don't do anything to the result except return it. The tailrec keyword is now successful, because the code was rewritten to delegate all activities to the recursive call. In addition, accumulator becomes an immutable value, eliminating the complaint we had for Iteration.kt.
factorial() is a common example for demonstrating tail recursion, and is one of the exercises for this atom. Another example is the Fibonacci sequence, where each new Fibonacci number is the sum of the previous two. The first two numbers are 0 and 1, which produces the following sequence: 0, 1, 1, 2, 3, 5, 8, 13, 21 ... This can be expressed recursively:
This implementation is terribly inefficient because the previously-calculated results are not reused. Thus, the number of operations grows exponentially:
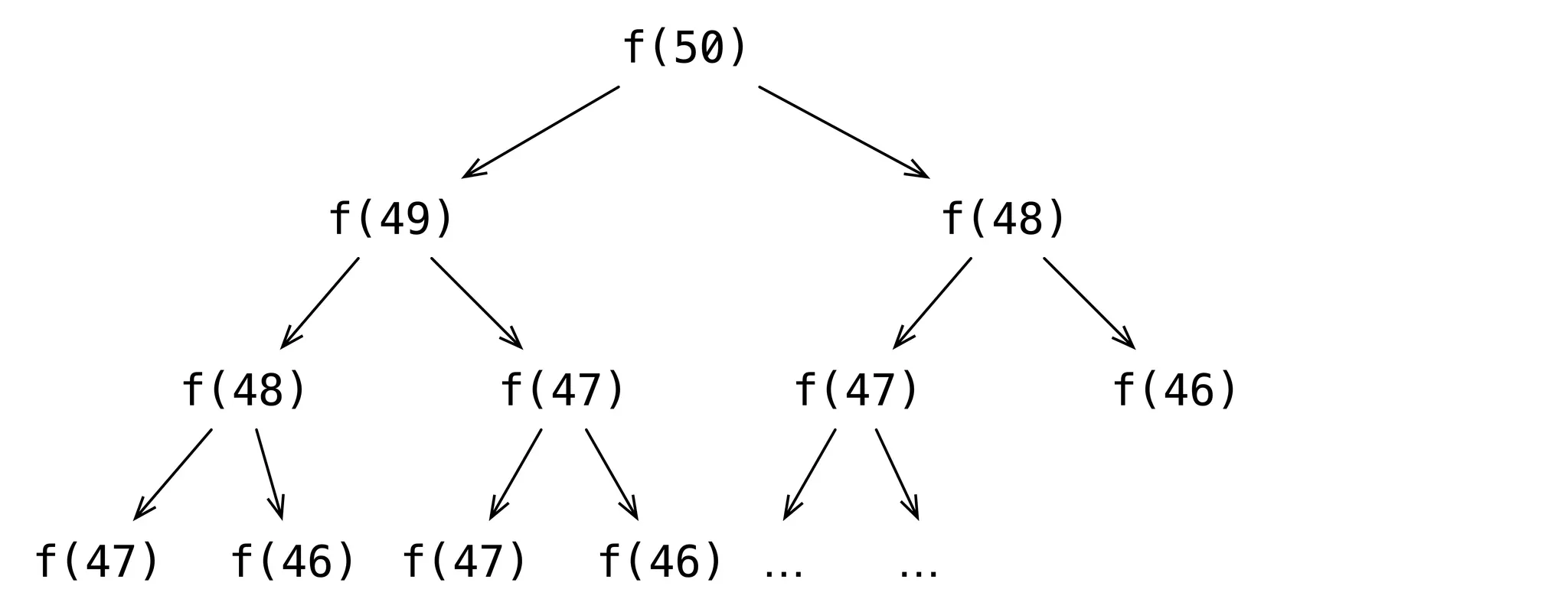
When computing the 50th Fibonacci number, we first compute the 49th and 48th numbers independently, which means we compute the 48th number twice. The 46th number is computed as many as 4 times, and so on.
Using tail recursion, the calculations become dramatically more efficient:
We could avoid the local fibonacci() function using default arguments. However, default arguments imply that the user can put other values in those defaults, which produce incorrect results. Because the auxiliary fibonacci() function is a local function, we don't expose the additional parameters, and you can only call fibonacci(n).
main() shows the first eight elements of the Fibonacci sequence, the result for 22, and finally the 50th Fibonacci number that is now produced very quickly.
