 들어가기 앞서
들어가기 앞서
단위 테스트 구조 챕터에서는 AAA 패턴(준비, 실행, 검증)으로 작성된 단위 테스트 구조를 살펴보고, 단위 테스트 프레임워크 xUnit을 소개한다. 하지만 코틀린, 자바 환경에서는 사용하지 않으므로 간단히 설명만 하고 넘어간다.
단위 테스트 명명법에 대해 유용하지 않은 명명 사례와 그 이유에 대해서 설명한다. 그 후 어떤 방식, 누구를 중점으로 명명을 지정 해야 되는지에 대해서도 살펴본다.
단위 테스트 프로세스를 간소화하는 데 도움을 주는 프레임워크(Junit5, Hamcrest)에 대해서 간단히 설명한다.
세미나 참여자들은 자바, 코틀린 언어를 주로 사용하기 때문에 책에서 설명하는 xUnit, Fluent Assertions 프레임워크에 대해서는 자세히 설명하지 않는다. 그렇다고 해서 기능에 대한 의미가 다른 것은 아니다. 비슷한 기능을 하는 프레임워크이다.
3.1 단위 테스트 구조
3.1 절에서는 준비, 실행, 검증 패턴을 사용해서 단위 테스트를 구성하는 방법, 피해야 하는 경우 그리고 테스트를 보다 쉽게 읽을 수 있는 방법을 설명한다.
3.1.1 AAA 패턴 사용
AAA 패턴은 각 테스트를 준비, 실행, 검증 부분으로 나눠서 사용한다.

AAA 패턴을 사용하면 스위트(테스트 집합) 내 모든 테스트들을 단순하고 균일한 구조를 가지게 된다. 즉, 일관성 있는 테스트 구조를 가지게 되어 유지 보수 비용이 줄어드는 장점을 가진다.
준비
•
테스트 대상 시스템(SUT)과 해당 의존성을 원하는 상태로 만든다.
실행
•
SUT에서 메서드를 호출하고 준비된 의존성을 전달하고 출력 값이 있다면 캡처한다.
검증
•
당연한 말이지만 결과를 검증한다. 여기서 말하는 결과는 반환 값, SUT와 협력자의 최종 상태, SUT가 협력자에 호출한 메서드 등을 지칭한다.
Given-When-Then 패턴
AAA 패턴과 유사한 Given-When-Then 패턴의 유일한 차이점은 프로그래머가 아닌
사람(비개발자)에게 Given-When-Then 구조가 더 읽기 쉽다는 것이다.
즉, Given-When-Then 패턴은 비개발자와 공유하는 테스트에 더 적합하다.
그렇다고 테스트를 시작할 때 무조건 준비 과정부터 시작하는 것은 아닐 수 있다.
테스트 주도 개발(TDD)를 사용한다고 가정해보자. 테스트 작성 시점은 기능이 개발(프로덕션 코드)하기 전이기 때문에 실패 테스트에 대해서 어떻게 동작할지 완벽하게 알지 못한다. 따라서 먼저 기대하는 동작으로 윤곽을 잡고(검증부터 시작), 이러한 기대에 부응하기 위한 시스템을 어떻게 개발할지 생각할 수도 있다.
TDD를 실천할 때 특정 동작이 무엇을 해야 하는지에 대한 목표 부터 잡고, 다른 것을 하기 전에 검증문을 작성(실제 문제 해결 능력)하는 것이 좋다.
물론, 테스트 전에 프로덕션 코드가 작성되어 있다면 준비 부터 시작하는 것이 좋다.
3.1.2 여러 개의 준비, 실행, 검증 구절 피하기

여러 개의 준비(Arrange), 실행(Act), 검증(Assert) 구절이 있다는 것은 테스트가 너무 많은 것을 한번에 검증한다는 뜻이다. 이러한 테스트는 여러 테스트로 나눠 작업하는 것이 좋다.
여러 개의 동작 단위를 검증하는 테스트 구조는 피하는 것이 좋다. 실행이 하나만 있다면 단위 테스트 범주에 있게끔 보장하고, 간단하고, 빠르며, 이해하기 쉽다. 즉, 각 동작을 고유의 테스트로 도출하자.
3.1.3 테스트 내 if 문 피하기
단위 테스트 안에 분기 구문(if 문)이 있다면, 이는 안티 패턴이다. 어느 테스트 간(단위 or 통합)에 분기가 없는 간단한 일련의 단계로 구성되어야 한다.
왜 if 문이 없어야 할까? 그 이유는 간단하다. 테스트가 한 번에 너무 많은 것을 검증하고 있다는 표시이기 때문이다. 이런 경우 반드시 여러 테스트로 나눠서 진행하자.
3.1.4 각 구절은 얼마나 커야 하는가?
AAA 패턴을 사용할 때 “각 구절의 크기는 얼마나 되어야 할까?”, “테스트가 끝난 후에 정리하는 종료 구절은 어떻게 구성해야 하는가?” 등과 같은 의문점을 가질 수 있다.
준비, 실행, 검증 구절의 크기에 대해서 알아보자.
준비 구절
일반적으로 준비 구절이 세 구절 중 가장 크다. 그렇다고 해서 준비 구절이 너무 커지게 되면, 같은 클래스 내 비공개 메서드 또는 별도의 팩토리 클래스로 도출하는 것이 좋다.
준비 구절에서 코드 재사용에 도움이 되는 두 가지 패턴으로 오브젝트 마더(Object Mother)와 테스트 데이터 빌더(Test Data Builder)가 있다.
Object Mother Pattern
Test Data Builder
실행 구절
실행 구절은 보통 코드가 한 줄이다. 만약 실행 구절이 두 줄 이상인 경우 SUT의 공개 API에 문제가 있을 수 있다.

그렇다면 왜 실행 구절이 두 줄 이상인 경우에 문제가 될까?
•
첫 번째 실행 구절 라인 → 고객이 상점에서 샴푸 다섯 개를 얻으려고 함
•
두 번째 실행 구절 라인 → 구매를 했으니 재고가 감소되는데, 첫 번째 라인의 purchase() 호출이 성공을 반환하는 경우에만 수행됨
어떤 문제가 있는지 알겠는가? 단일 작업을 수행하는 데 두 개의 메서드의 호출이 필요한 것을 알 수 있다.
비즈니스 관점에서 보면 구매가 정상적으로 이뤄지면 고객의 제품 획득 과 매장 재고 감소 라는 두 가지 결과가 만들어진다. 이러한 결과는 같이 만들어져야 하고, 이는 단일 공개 메서드가 있어야 한다는 뜻을 의미한다.
이러한 모순을 불변 위반(invariant violation)이라고 하며, 잠재적 모순으로부터 코드를 보호 하는 행위를 캡슐화(encapsulation)라고 한다.
쇼핑몰 애플리케이션이 있다고 가정하자.
A 고객은 3개의 재고가 남아있는 옷을 3개 구매하기 위해 주문을 진행했다.
B 고객도 동일한 옷을 구매하려고 하는데 분명히 재고가 없어야 하는데 구매가 진행되고 영수증까지 발급되었다.
이러한 치명적인 결함이 비즈니스에 크게 악영향을 미치게 될 것이다.
왜 이런 문제가 발생했을까? 코드의 캡슐화가 제대로 지켜지지 않았기 때문이다.
위의 예제에서 purchase 메서드의 한 부분으로 고객이 매입한 재고를 제거하고, 클라이언트 코드에 의존하지 않아야 했다. 불변을 지키는 한, 불변 위반을 초래할 수 있는 잠재적인 행동을 제거해야 한다.
물론 무조건이란 없다. 실행 구절을 한 줄로 하는 지침은 비즈니스 로직을 포함하는 대부분의 코드에 적용되지만, 유틸리티 또는 인프라 코드는 덜 적용된다.
3.1.5 검증 구절에는 검증문이 얼마나 있어야 하는가
검증 구절
2장에서 살펴봤듯이, 가능한 한 가장 작은 코드를 목표로 하는 전제는 올바르지 않다. 단위 테스트의 단위는 동작의 단위로 두어야 한다. 단일 동작 단위는 여러 결과를 낼 수 있으며, 하나의 테스트로 그 모든 결과를 평가하는 것이 좋다. 이렇다 해도 프로덕션 코드에서 추상화가 누락될 수 있으니, 검증 구절이 너무 커지는 것을 경계해야 한다.
•
SUT에서 반환된 객체 내에서 모든 속성을 검증하지 말자
•
객체 클래스 내 적절한 동등 멤버(equality member)를 정의하는 것이 좋다 → 단일 검증문으로 객체를 기대값과 비교할 수 있다.
3.1.6 종료 단계는 어떤가
테스트에 의해 작성된 파일을 지우거나 데이터베이스 연결을 종료할 때, 일반적으로 종료 구절을 별도의 메서드로 도출하여 클래스 내 모든 테스트에서 재사용 된다(AAA 패턴에서는 사용안함).
대부분의 단위 테스트는 프로세스 외부에 종속적이지 않으므로 종료 구절이 필요 없지만, 통합 테스트에서 사용되니 3부에서 자세하게 다룬다.
3.1.7 테스트 대상 시스템 구별하기
SUT는 애플리케이션에서 호출하고자 하는 동작에 대한 진입점을 제공하는 중요한 역할을 한다.
동작은 여러 클래스에 걸쳐 있을 만큼 클 수도 있고 단일 메서드처럼 작을 수 있다. 하지만 진입점은 오직 하나만 존재할 수 있다.

따라서 SUT를 의존성과 구분하는 것이 좋다. 간단한 해결책으로 테스트 내 SUT 이름을 sut로 구분하여 사용하자.
3.1.8 준비, 실행, 검증 주석 제거하기
테스트 내에서 특정 부분이 어떤 구절에 속해 있는지 파악하는 데 시간을 많이 들이지 않도록 서로 구분하는 것이 중요하다.
•
각 구절의 시작하는 코드 위에 주석 달기
•
빈 줄로 분리하기
빈 줄로 분리하는 것이 간결성과 가독성 사이에서 균형을 잡을 수 있다. 상황에 따라 주석을 제거할 수 있으면 제거하고 빈 줄로 분리하고, 그렇지 않은 경우에는 주석으로 구분하자.
3.2 xUnit 테스트 프레임워크 살펴보기
xUnit 단위 테스트 프레임워크는 .NET 환경에서만 작동하지만, 모든 객체지향 언어(java, kotlin, c++ 등)의 단위 테스트 프레임워크와 매우 비슷하게 사용된다.
.NET 환경에서 사용되는 대표적인 단위 테스트 프레임워크
•
xUnit → xUnit의 강점은 다른 단위 테스트 프레임워크 보다 더 깨끗하고 간결하다.
•
NUnit
•
Microsoft MSTest
xUnit의 [Fact] 특성은 테스트가 아닌 사실이라는 것을 알려준다. 이는 xUnit 프레임워크의 한정적인 의미만이 아니다.
“각 테스트는 이야기가 있어야 한다”
이 이야기는 문제 영역에 대한 개별적이고 원자적인 사실 또는 시나리오이며, 테스트가 통과한다는 것은 이 사실 또는 시나리오가 실제 사실이라는 증거이다. 테스트가 실패하면 이야기가 더 이상 유효하지 않아 테스트를 다시 작성해야 하거나 시스템 자체(ex: 프로덕션 코드, 설계…)를 수정해야 한다.
단위 테스트를 작성할 때는 이런 사고방식을 갖는 것이 좋으며, 애플리케이션 동작에 대해 고수준의 명세가 있어야 한다. 이상적으로 생각했을 때 프로그래머(개발자)뿐만 아니라 비즈니스 담당자(비개발자)에게도 의미가 있어야 한다.
3.3 테스트 간 테스트 픽스처 재사용
3.3 장에서는 테스트에서 언제 어떻게 코드를 재사용 하는 것이 좋은가에 대해서 알아본다.
준비 구절에서 코드를 재사용 하는 것이 테스트를 줄이면서 단순화하기 좋은 방법이고, 올바른 방법에 대해서 알아본다.
테스트 픽스처
1. 테스트 픽스처는 테스트 실험 대상 객체다. SUT로 전달되는 인수를 말한다. 예를 들면, 데이터베이스에 있는 데이터나 하드 디스크의 파일일 수도 있다. 이러한 객체는 각 테스트 실행 전에 정해진 고정 상태로 유지하기 때문에 동일한 결과를 생성한다.
2. 다른 정의는 NUnit 테스트 프레임워크에서 비롯된다. NUnit에서 [TextFixture]는 테스트가 포함된 클래스를 표시하는 특성이다.
테스트 픽스처를 준비할 때 코드가 많이 작성되는 경우가 종종 있다. 이러한 준비 구절을 별도의 메서드나 클래스로 도출한 후 테스트 간에 재사용 하는 것이 좋다.
3.3 절에 재사용 하는 두 가지 방법에 대해서 알아본다(올바르지 못한 방법 / 올바른 방법).
테스트 생성자에서 픽스처를 초기화 하는 방법(올바르지 못한 방법)
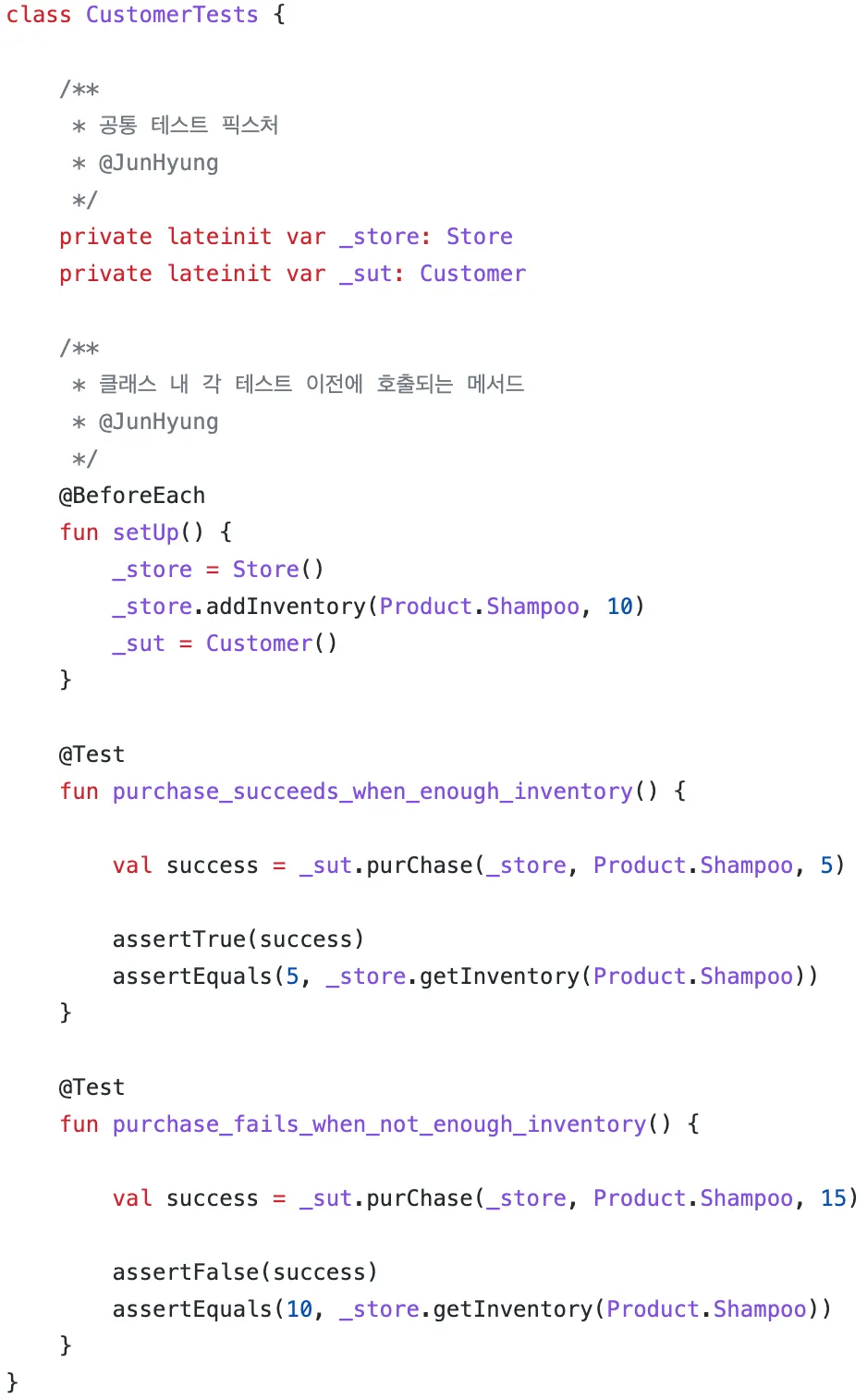
이 방법으로 테스트 코드의 양을 크게 줄일 수 있고, 테스트 픽스처 구성을 전부 또는 대부분 제거할 수 있다. 하지만 두 가지 중요한 단점이 발생한다.
•
테스트 간 결합도 증가
•
테스트 가독성 저하
3.3.1 테스트 간의 높은 결합도는 안티 패턴이다.
위의 예제 코드는 모든 테스트가 서로 결합되어 있는 걸 확인할 수 있다. 즉, 테스트의 준비 로직을 수정하면 클래스의 모든 테스트에 영향을 미친다.
//수정 전
_store.addInventory(Product.Shampoo, 10)
//수정 후
_store.addInventory(Product.Shampoo, 15)
Kotlin
복사
상점의 초기 상태에 대한 가정을 무효화하므로, 테스트 함수의 가정을 모두 수정하지 않는 한 테스트가 실패하게 된다.
테스트를 수정해도 다른 테스트에 영향을 주어서는 안된다. 이 지침을 따르려면 테스트 클래스에 공유 상태를 두지 말아야 한다.
private lateinit var _store: Store
private lateinit var _sut: Customer
Kotlin
복사
3.3.2 테스트 가독성을 떨어뜨리는 생성자 사용
테스트 코드만 보고 전체 그림이 그려져야 하는데, 준비 코드를 생성자로 추출하게 되면 테스트 가독성이 떨어지게 된다.
준비 로직이 별로 없더라도(ex: 픽스처의 인스턴스화만 있을 때) 테스트 메서드로 바로 옮기는 것이 좋다.
3.3.3 더 나은 테스트 픽스처 재사용법
비공개 팩토리 메서드 사용(올바른 방법)

공통 초기화 코드를 비공개 팩토리 메서드로 추출해서 코드를 짧게 하고, 테스트 진행 상황에 대한 전체 맥락을 유지할 수 있다. 가장 중요한 점은 비공개 메서드를 충분히 일반화하는 한 테스트가 서로 결합되지 않는다.
즉, 테스트에 픽스처를 어떻게 생성할 지 지정할 수 있다.
val store: Store = createStoreWithInventory(Product.Shampoo, 10)
Kotlin
복사
위의 코드 스니펫을 보면 팩토리 메서드를 통해 “상점에 샴푸 열 개 추가”하라고 테스트에 명시되어 있다. 매우 읽기 쉽고 재사용이 가능하다. 또한 팩토리 메서드 내부를 알아볼 필요가 없기 때문에 가독성이 매우 좋다.
테스트 픽스처 재사용 규칙에 한 가지 예외가 있다. 모든 테스트 또는 거의 대부분의 테스트에 사용되는 경우(ex: 데이터베이스와 작동하는 통합테스트 등) 생성자에 픽스처를 인스턴스화 할 수 있다.
이러한 모든 테스트는 데이터베이스 연결이 필요하며, 이 연결을 한 번 초기화한 다음 어디에서나 재사용할 수 있다. 기초 클래스(Base Class)에 초기화하는 것보단, 클래스 생성자에서 데이터베이스 연결을 초기화하는 것이 좋다.
3.4 단위 테스트 명명법
올바른 명칭은 테스트가 검증하는 내용과 기본 시스템의 동작을 이해하는 데 도움이 된다.
가장 유명하지만 가장 도움이 되지 않는 방법 중 하나를 살펴보자
[테스트 대상 메서드]_[시나리오]_[예상 결과]
•
테스트 대상 메서드 → 테스트 중인 메서드의 이름
•
시나리오 → 메서드를 테스트하는 조건
•
예상 결과 → 현재 시나리오에서 테스트 대상 메서드에 기대하는 것
이 방법은 동작 대신 구현 세부 사항에 집중하게끔 유도하기 때문에 도움이 되지 않는다.
이러한 방법 보단, 간단하고 쉬운 영어 구문이 훨씬 더 효과적이며, 엄격한 명명 구조에 얽매이지 않고 표현력이 더욱 뛰어나다.
//간단한 영어 문구
fun sum_of_two_numbers() { ... }
//[테스트 대상 메서드]_[시나리오]_[예상 결과] 명명법
fun sum_twoNumbers_returnSum() { ... }
Kotlin
복사
프로그래머는 [테스트 대상 메서드]_[시나리오]_[예상 결과] 명명법을 이해할 수 있겠지만, 관련 지식이 충분하지 않는 경우에는 이해하기 쉽지 않을 것이다.
•
sum은 왜 테스트 이름으로 두 번이나 나타나는가?
•
return은 어떤 표현인가?
•
합계는 어디로 반환되는가?
결국 단위 테스트는 도메인 전문가가 아닌 프로그래머를 위해 프로그래머가 작성한다. 그래서 프로그래머만 이해할 수 있는 수수께끼 같은 이름으로 작성하는 경우가 많다. 하지만 수수께끼 같은 이름은 프로그래머든 아니든 모두가 이해하는데 부담이 될 수 밖에 없다(가독성 저하).
테스트가 정확히 무엇을 검증하는지, 비즈니스 요구사항과 어떤 관련이 있는지 파악할 수 있게 명명에 더욱 노력해야 한다. 이런 노력을 하지 않으면 전체 테스트 스위트 유지비가 천천히 증가할 것이다(ex: 동료가 작성한 테스트를 이해할 때).
3.4.1 단위 테스트 명명 지침
표현력 있고 읽기 쉬운 테스트 이름을 짓기 위해 다음 지침을 따르자
•
엄격한 명명 정책을 따르지 않는다. 표현의 자유를 허용하자
•
문제 도메인에 익숙한 비개발자들(ex: 도메인 전문가, 비즈니스 분석가)에게 시나리오를 설명하는 것처럼 테스트 이름을 짓자.
•
단어를 밑줄(underscope) 표시로 구분하자. 긴 이름에서 가독성을 향상시킨다.
테스트 클래스 이름을 지정할 때 [클래스명]Tests 패턴을 사용하지만, 테스트가 해당 클래스만 검증하는 것으로 제한하는 것은 절대 아니다. 단위 테스트에서 단위는 동작의 단위지, 클래스의 단위가 아닌 것을 명심하자.
3.4.2 예제: 지침에 따른 테스트 이름 변경
테스트 하나를 예로 들어서 설명한 지침에 따라 이름을 개선해보자. 이 예제의 테스트 이름은 가독성에 도움이 되지 않는 엄격한 명명 정책으로 작성됐다([테스트 대상 메서드]_[시나리오]_[예상 결과]).

// [테스트 대상 메서드]_[시나리오]_[예상 결과] 명명법
fun isDeliveryValid_invalid_returnFalse() { ... }
// 테스트 이름을 쉬운 영어로 수정
fun delivery_with_invalid_date_should_be_considered_invalid() { ... }
Kotlin
복사
•
이름이 프로그래머가 아닌 사람들에게 납득되고, 마찬가지로 프로그래머도 쉽게 이해할 수 있음
•
SUT의 메서드 이름(isDeliveryValid)은 더 이상 테스트 명에 포함되지 않음
테스트명 내 테스트 대상 메서드
테스트 이름에 SUT의 메서드 이름을 포함하지 말자.
코드를 테스트하는 것이 아닌 애플리케이션의 동작을 테스트하는 것을 유의하자. SUT는 단지 진입점, 동작을 호출하는 수단일 뿐이다.
이 지침의 유일한 예외는 유틸리티 코드를 작업할 때다. 유틸리티 코드는 비즈니스 로직이 없고, 코드의 동작이 단순한 보조 기능에서 벗어나지 않으므로 비즈니스 담당자에게는 아무런 의미가 없다.
테스트 메서드의 이름을 더 개선해보자.
•
배송 날짜가 무효하다 → 과거의 어느 날짜 → 배송 날짜를 미래에서만 선택할 수 있어야 한다.
fun delivery_with_past_date_should_be_considered_invalid() { ... }
Kotlin
복사
나아지기는 했지만 여전히 이상적이지 않고 너무 장황하다. considered(고려하다)라는 단어를 제거해도 의미가 퇴색되지 않는다.
fun delivery_with_past_date_should_be_invalid() { ... }
Kotlin
복사
should be 문구는 또 다른 일반적인 안티 패턴이다. 하나의 테스트는 동작 단위에 대해 단순하고 원자적인 사실이기 때문에 소망이나 욕구가 들어가면 안된다.
•
should be → is
fun delivery_with_past_date_is_invalid() { ... }
Kotlin
복사
거의 다 왔다. 이제 기초 영문법을 지키도록 바꿔보자. 관사를 붙이면 테스트를 완벽하게 읽을 수 있다.
•
관사 a 추가
fun delivery_with_a_past_date_is_invalid() { ... }
Kotlin
복사
명명법 최종 단계 정리
3.5 매개변수화된 테스트 리팩터링 하기
아쉽게도 테스트 하나로는 동작 단위를 완벽하게 설명하기에 충분하지 않다. 이 단위는 일반적으로 여러 구성 요소를 포함하며, 각 구성 요소는 자체 테스트로 캡처 해야 한다. 동작이 복잡하면, 이를 설명하는 테스트 수가 증가할 것이고 이로 인해 관리가 어려워질 것이다.
대부분의 단위 테스트 프레임워크는 매개변수화된 테스트(parameterized test)를 사용해 유사한 테스트를 묶을 수 있는 기능을 제공한다.
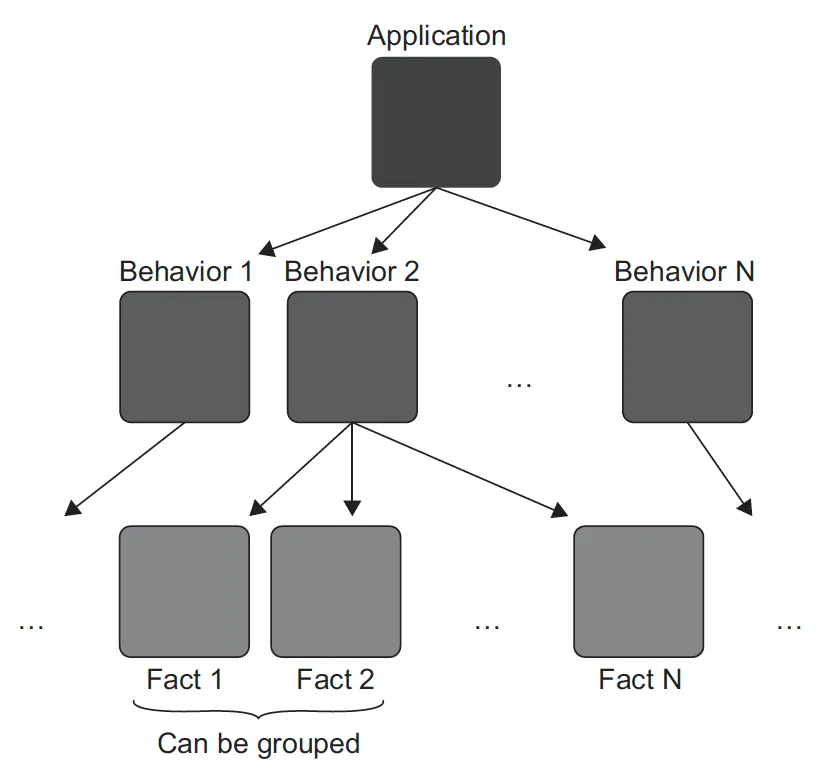
일반적인 애플리케이션은 여러 가지 동작을 나타낸다. 동작의 복잡도 클수록, 충분히 설명하기 위해서 더 많은 사실이 필요하다. 각 사실을 테스트로 표현한다(ex: 성공, 실패). 매개변수화된 테스트를 사용하면 유사한 사실을 단일 테스트 메서드로 묶을 수 있다.
이전 예제에 이어서 별도의 테스트에 기술된 각 동작 구성 요소를 살펴본 다음, 이 테스트들을 그룹핑하는 방법을 알아보자.
•
가장 빠른 배송일이 오늘로부터 이틀 후가 되도록 작동하는 배송 기능이 있다고 가정
•
지난 배송일, 오늘 배송일, 내일 배송일, 모레 배송일의 날짜를 확인하는 테스트가 필요
fun delivery_with_a_past_date_is_invalid()
fun delivery_for_today_is_invalid()
fun delivery_for_tomorrow_is_invalid()
fun the_sonnest_delivery_date_is_two_days_from_now()
Kotlin
복사
기능은 같은데 배송 날짜만 다르다고 해서 네 개의 메서드를 각각 테스트 하는 것은 비효율적이다. 테스트 코드의 양을 줄이기 위해 이러한 테스트를 하나로 묶으면 훨씬 좋을 것이다.
책에서는 xUnit에 있는 매개변수화된 테스트 기능을 사용하지만, 본 세미나에서는 JUnit 5에서 제공하는 매개변수 테스트 기능을 사용한다.
매개변수 테스트(JUnit 5)
매개변수화된 테스트를 사용하면 테스트 코드의 양을 크게 줄일 수 있지만, 비용이 발생한다.
•
테스트 메서드가 나타내는 사실을 파악하기 어려워짐
•
매개변수가 많을수록 더욱 어려워짐

테스트 코드의 양과 그 코드의 가독성은 서로 상충된다.
저자의 경험에 따르면 입력 매개변수 만으로 테스트 케이스를 판단할 수 있다면 긍정적인, 부정적인 케이스를 하나의 메서드로 두는 것이 좋다.
그렇지 않은 경우에만 긍정적인 테스트 케이스를 도출하자. 또한 동작이 너무 복잡하면 매개변수화된 테스트를 아예 사용하지 않고, 긍정적, 부정적 케이스 모두 각각 고유의 테스트 메서드로 나타내자.
3.5.1 매개변수화된 테스트를 위한 데이터 생성
테스트 데이터가 간단한 경우에는 @ValueSource 를 사용하면 되지만, 그렇지 않은 경우도 분명히 있을 것이다.
그럴 경우 테스트 메서드에 공급할 사용자 정의 데이터를 생성하는 메서드를 정의하면 된다. @MethodSource 를 사용해서 다소 복잡한 사용자 정의 데이터(객체)를 인자로 넘기자.

@JvmStatic ?
3.6 검증문 라이브러리를 사용한 테스트 가독성 향상
책에서 테스트 가독성을 높이기 위해 Fluent Assertions 라이브러리를 설명한다. JUnit에서도 가독성을 높여주는 여러 프레임워크가 제공되지만, 그 중에서 hamcrest에 대해서 간단히 알아본다.
hamcrest는 JUnit에서 사용되는 Matcher 라이브러리이다. 테스트 표현식을 작성할 때 좀 더 문맥적으로 자연스럽고 우아한 문장을 만들 수 있도록 도와준다. 사용자 정의 assertion Matcher 작성을 지원하여 검증 규칙을 선언적으로 정의할 수 있다.
Matcher 라이브러리
필터나 검색등을 위해 값을 비교할 때 더 편리하게 사용하도록 도와주는 라이브러리이다.
동일한 알파벳을 재배열하여 만들어낸 문장이나 단어를 제공한다.
hamcrest에서 제공하는 다양한 패키지, 코어, 오브젝트, 로지컬, 컬렉션들이 있지만 대표적으로 가장 많이 사용하는 assertThat에 대해서만 살펴본다.
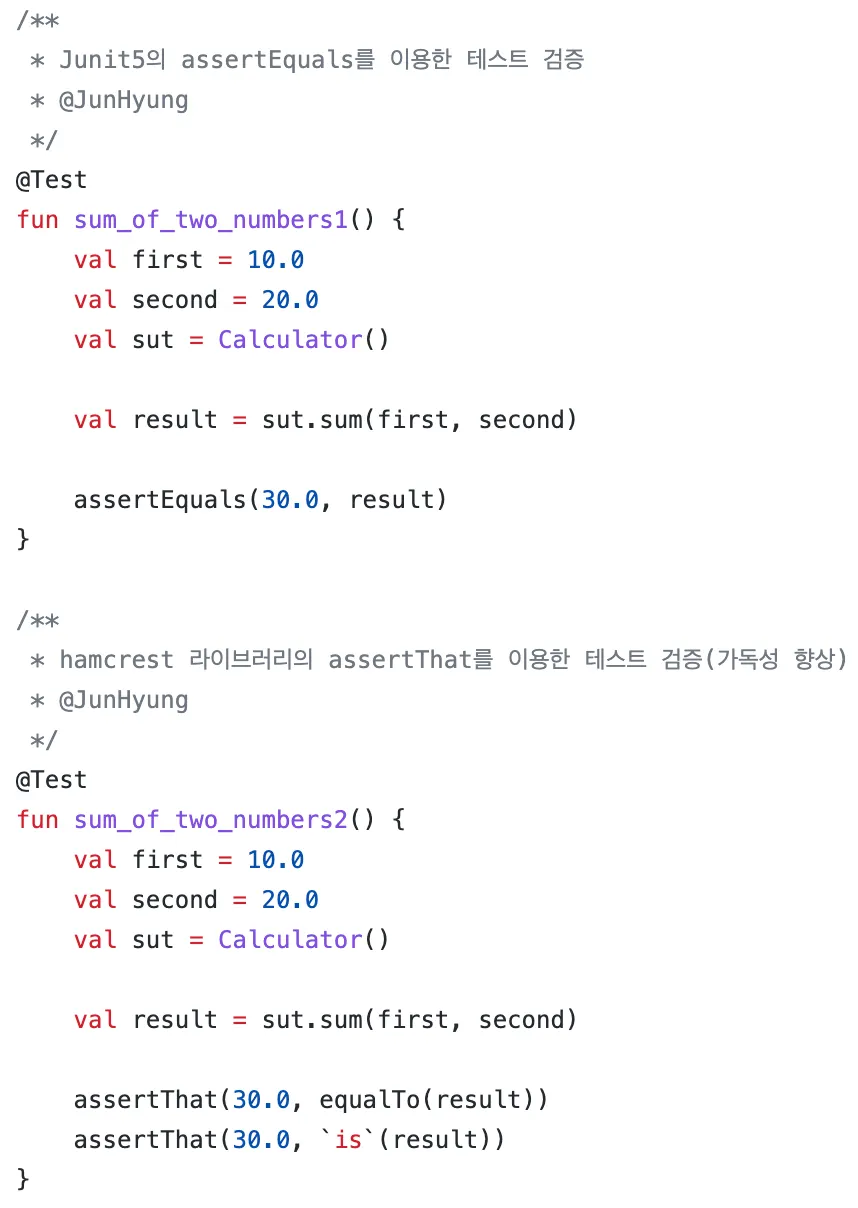
assertEquals 보다 assertThat 의 `is` 혹은 equalTo를 사용하면 가독성이 좋아진 것을 확인할 수 있다.

