
Think of the Internet as a giant, expanding city, full of places to see and things to do. You and the other residents and tourists of this booming community would use standard naming convensions for the city's vast attractions and services. You'd use street addresses for museums, restuarants, and people's homes. You'd use phone numbers for the fire department, the boss's secretary, and your mother, who says you don't call enough.
Everything has a standardized name, to help sort out the city's resources. Books have ISBN numbers, buses have route numbers, bank accounts have account numbers, and people have social security numbers. Tomorrow you will meet your business partners at gate 31 of the airport. Every morning you take a Red-line train and exit at Kendall Square station.
And because everyone agreed on on standards for these different names, we can easily share the city's treasures with each other. You can tell the cab driver to take you to 246 McAllister Street, and he'll know what you mean (even if he takes the long way).
Uniform resource locators (URLs) are the standardized names for the Internet's resources. URLs point to pieces of electronic information, telling you where they are located and how to interact with them.
In this chapter, we'll cover:
•
URL syntax and what the various URL components mean and do
•
URL shortcuts that many web clients support, including relative URLs and expandomatic URLs
•
URL encoding and character rules
•
Common URL schemes that support a variety of Internet information systems
•
The future of URLs, including uniform resource anems (URNs) —a framework to support objects that move from place to place while retaining stable names
1. Navigating the Internet's Resources
URLs are the resource locations that your browser needs to find information. They let people and application find, use, and share the bilions of data resources on the Internet. URLs are the usual human access point to HTTP and other protocols: a person points a browser at a URL and, behind the scenes, the browser sends the appropriate protocol message to get the resource that the person wants.
URLs actually are a subset of a more general class of resource identifier called a uniform resource identifier, or URI. URIs are a general concept comprsied of two main subsets, URLs and URNs. URLs identify resources by describing where resources are located, whereas URNs identify resources by name, regardless of where they currently reside.
The HTTP specification uses the more general concepts of URIs as its resource identifiers; in practice, however, HTTP applications deal only with the URL subset of URIs. Throughout this book, we'll sometimes refer to URIs and URLs interchangeably, but we're almost always talking about URLs.
Say you want to fetch the URL http://www.joes-hardware.com/seasonal/index-fall.html:
•
The first part of the URL (http) is the URL scheme. The scheme tells a web client how to access the resource.
•
The second part of the URL (www.joes-hardware.com) is the server location. This tells the web client where the resource is hosted.
•
The third part of the URL (/seasonal/index-fall.html) is the rosource path. The path tells what particular local resource on the server is being requested.
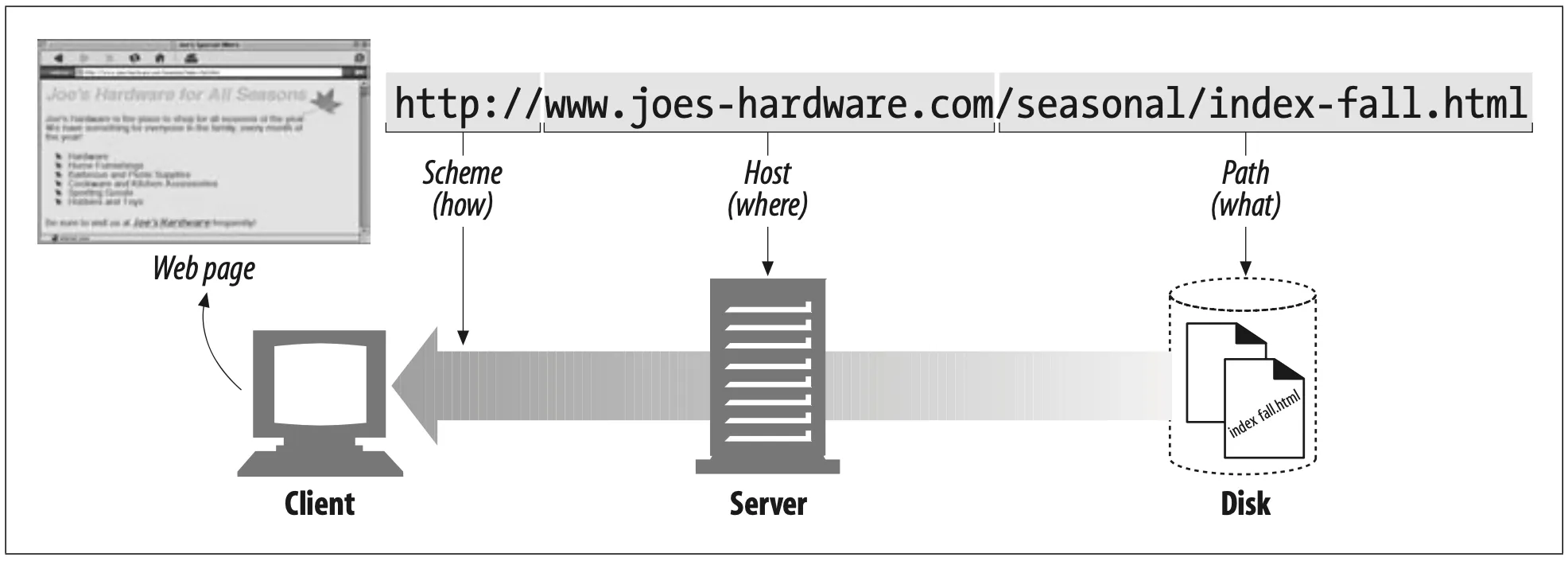
Figure 2-1. How URLs relate to browser, machine, server, and location on the server's filesystem
URLs can direct you to resources available through protocols other than HTTP. They can point you to any resource on the Internet. from a person's email account:
mailto:president@whitehouse.gov
to files that are available through other protocols, such as the File Transfer Protocol (FTP):
ftp://htp.lots-o-books.com/pub/complete-price-list.xls
to movies hosted off of streaming video servers:
rtsp://www.joes-hardware.com:554/interview/cto_video
URLs provide a way to uniformly name resources. Most URLs have the same "shceme://server location/path" structure. So, for every resource out there and every way to get those resources, you have a single way to name each resource so that anyone can use that name to find it. Howerver, this wasn't always the case.
1.1. The Dark Days Before URLs
Skip...
2. URL Syntax
URLs provide a means of locating any resource on the Internet, but these resources can be accessed by different schemes (e.g., HTTP, FTP, SMTP), and URL syntax varies from scheme to scheme.
Does this mean that each different URL scheme has a radically different syntax? In practice, no. Most URLs adhere to a general URL syntax, and there is significant overlap in the sytle and syntax between different URL schemes.
Most URL schemes base their URL syntax on this nine-part general format:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
Almost no URLs contain all these components. The three most important parts of a URL are the sheme, the host, and the path. Table 2-1 summarized the various components.
기본 보기
Search
For example, consider the URL http://www.joes-hardware.com:80/index.html. The scheme is "http", the host is "www.joes-hardware.com", the port is "80", and the path is "/index.html".
2.1. Schemes: What Protocol to Use
The scheme is really the main identifier of how to access a given resource; it tells the application interpreting the URL what protocol it needs to speak. In out simple HTTP URL, the scheme is simply "http".
The scheme component must start with an alphabetic character, and it is separated from the rest of the URL by the first ":" character. Scheme names are case-insensitive, so the URLs “http://www.joes-hardware.com” and “HTTP://www.joes-hardware.com” are equivalent.
2.2. Hosts and Ports
To find a resource on the Internet, an application needs to know what machine is hosting the resource and where on that machine it can find the server that access to the desired resource. The host and port components of the URL provide these two pieces fo information.
The host component identifies the host machine on the Internet that has access to the resource. The name can be provided as a hostname, as above ("www.joes-hardware.com") or as IP address. For example, the following two URLs point to the same resource—the first refers to the server by its hostname and the second by its IP address:
http://www.joes-hardware.com:80/index.html
http://161.58.228.45:80/index.html
The port component identifies the network port on which the server is listening. For HTTP, which uses the underlying TCP protocol, the default port is 80.
2.3. Usernames and Passwords
More interesting components are the user and password components. Many servers require a username and password before you can access data through them. FTP servers are a common example of this. Here are a few examples:
ftp://ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous@ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous:my_passwd@ftp.prep.ai.mit.edu/pub/gnu
http://joe:joespasswd@www.joes-hardware.com/sales_info.txt
The first example has no user or password compoent, just our standard scheme, host, and path. If an application is using a URL scheme that requires a username and password, such as FTP, it generally will insert a default username and password if they aren't supplied. For example, if you hand your browser an FTP URL without specifying a username and password, it will insert "anonymous" for your username and sen a default password (Internet Explorer sends "IEUser", while Netscape Navigator sends "mozilla").
The second example shows a username being specified as "anonymous". This username, combined with the host component, looks just like an email address. The "@" character separates the user and password component from the rest of the URL.
In the third example, both a username ("anonymous") and password ("my_passwd") are specified, separated by the ":" character.
2.4. Paths
The path component of the URL specifies where on the server machine the resource lives. The path often resembles a hierarchical filesystem path. For example:
http://www.joes-hardware.com:80/seasonal/index-fall.html
The path in this URL is "seasonal/index-fall.html", which resembles a filesystem path on a Unix filesystem. The path is the information that the server needs to locate the resource. The path component for HTTP URLs can be divided into path segments separeted by "/" characters. Each path segment can have its own params component.
2.5. Parameters
For many schems, a simple host and path to the object just aren't enough. Aside from what port the server is listeningto and even whether or not you have access to the resource with a username and password, many protocols require more information to work.
Applications inperpreting URLs need these protocol parameters to access the resource. Otherwisw, the server on the other side might not service the request or, worse yet, might service it wrong. For example, take a protocol like FTP, which has two modes of transfer, binary and text. You wouldn't want your binary image transferred in text mode, because the binary image could be scrambled.
To give applications the input parameters they need in order to talk to the server corectly, URLs have a params component. This component is just a list of name/value pairs in the URL, separated from the rest of the URL (and from each other) by ";" characters. They provide applications with any addtional information that they need to access the resource. For example:
ftp://prep.ai.mit.edu/pub/gnu;type=d
In this example, there is one param, type=d, where the name of the param is "type" and its value is "d".
As we mentioned earlier, the path component for HTTP URLs can be broken into path segments. Each segment can have its own params. For example:
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=true
In this example there are two path segments, harmmers and index.html. The hammers path segment has the param sale, and its value is false. The index.html segment has the param graphics, and its value is true.
2.6. Query Strings
Some resources, such as database services, can be asked questions or queries to narrow down the type of resource being requested.
Let's say Joe's Hardware store maintains a list of unsold inventory in a database and allows the inventory to be queried, to see whether products are in stock. The following URL might be used to query a web database gateway to see if item number 12731 is available:
http://www.joes-hardware.com/inventory-check.cgi?item=12731
For the most part, this resembles the other URLs we have looke at. What is new is everything to the right of of the question mark (?). This is called the query component. The query component of the URL is passed along to a gateway resource, with the path component of the URL identifying the gateway resource. Basically, gateways can be thought of as access points to other applications (we discuss gateways in detail in Chapter 8).
Figure 2-2 shows an example of a query component being passed to a server that is acting as a gateway to Joe's Hardware's inventory-checking application. The query is checking whether a particular item, 12731, is inventory in size large and color blue.
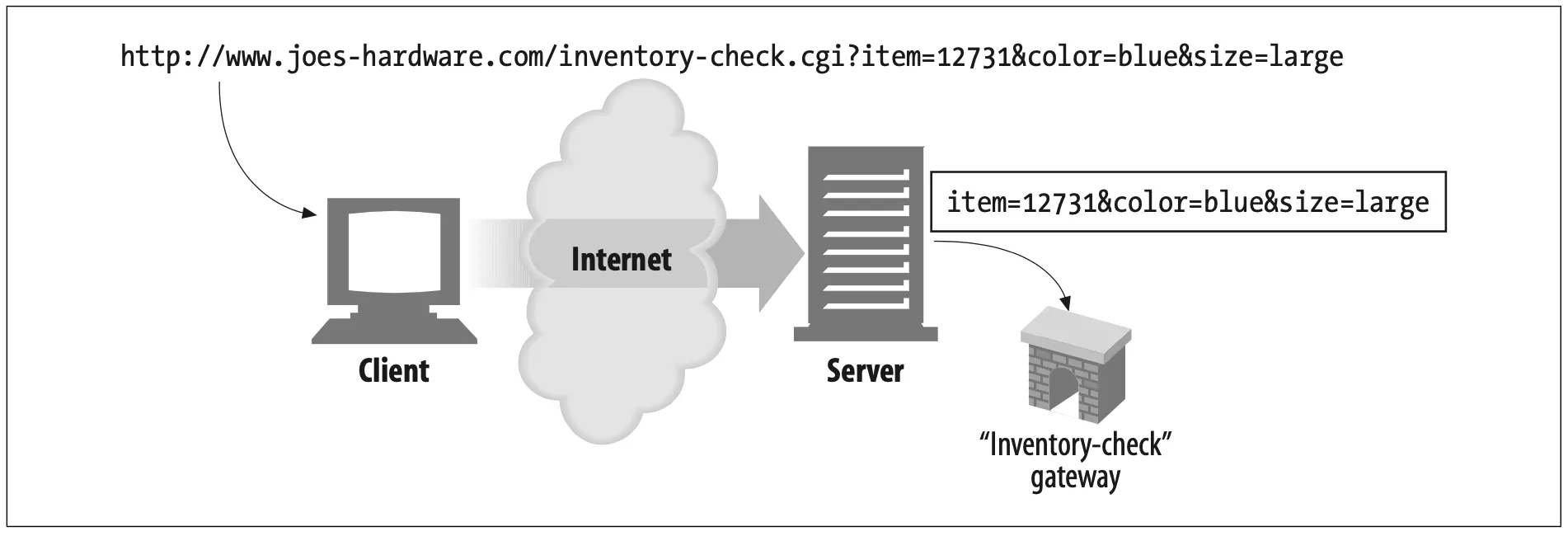
Figure 2-2. The URL query component is sent along to the gateway application
There is no requirement for the format query component, except that some character are illegal, as we'll see later in this chapter. By convertion, many gateways expect the query strinbg to be formatted as a series of "name=value" pairs, separated by "&" characters:
http://www.joes-hardware.com/inventory-check.cgi?item=12731&color=blue
In this example, there are two name/value pairs in the query component: item=12731 and color=blue.
2.7. Fragments
Some resource types, such as HTML, can be divided further than just the resource level. For example, for a single, large text document with sections in it, the URL for the resource would point to the entire document, but ideally you could specify the sections within the resource.
To allow referencing of parts or fragments of a resource, URLs support a frag component to identify pieces within a resource. For example, a URL could point to a particular image or section within an HTML document.
A fragment dangles off the right-hand side of a URL, preceded by a # character. For example:
http://www.joes-hardware.com/tools.html#drills
In this example, the fragment drills reference a portion of the /tools.html web page located on the Joe's Hardware web server. The portion is named "drills".
Because HTTP servers generally deal only with entire objects, not with fragments of objects, clients don't pass fragments along to servers (see Figure 2-3). After your browser gets the entire resource from the server, it then uses the fragment to display the part of the resource in which you are interested.
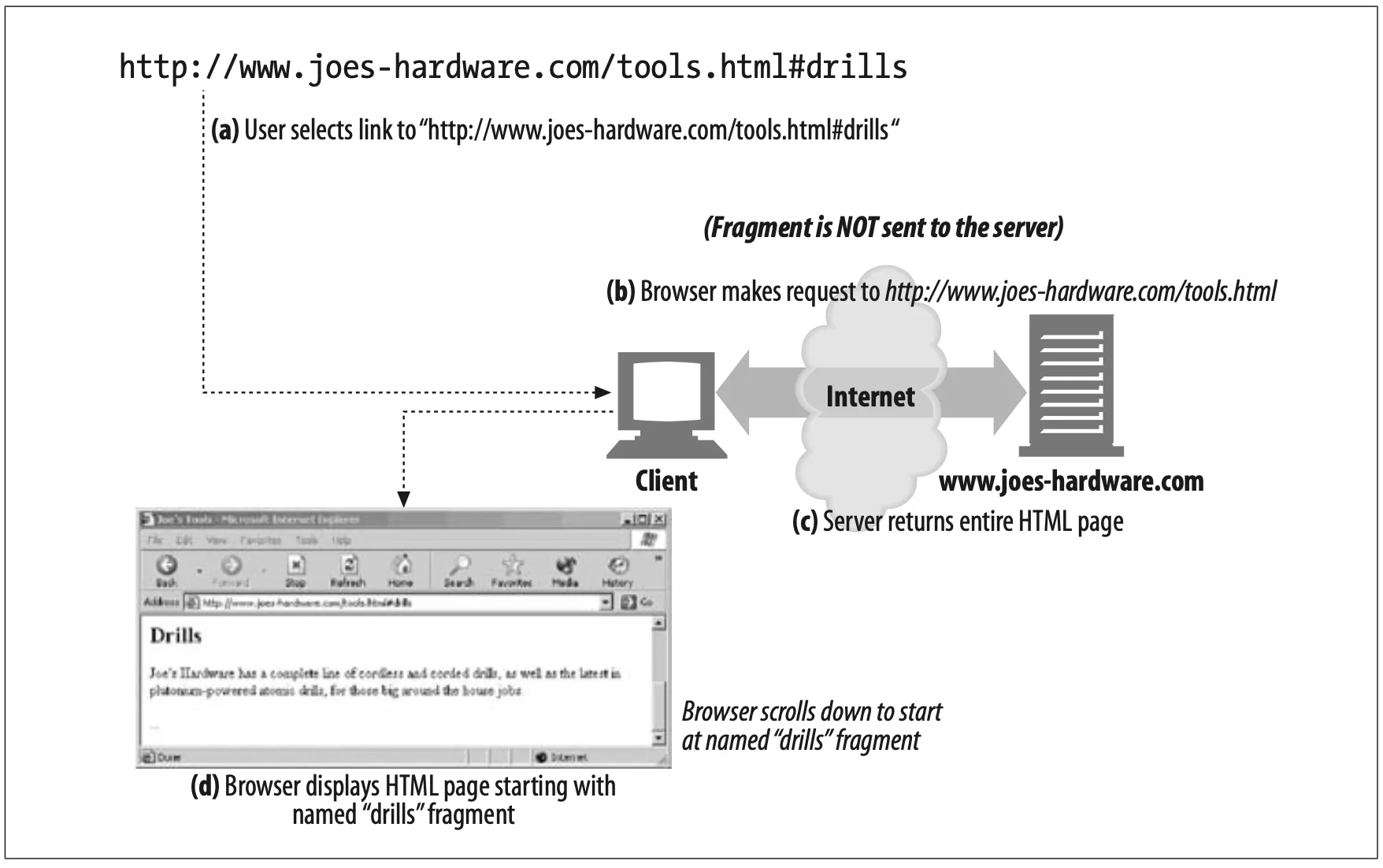
Figure 2-3. The URL fragment is used only by the client, because the server deal with entire objects
3. URL Shortcuts
Web clients understand and use a few URL shortcuts. Relative URLs are a convenient shorthand for specifying a resource within a resource. Many browsers also support "automatic expansion" of URLs, where the user can type in a key (memorable) part of a URL, and the browser fills in the rest. This is explained in "Expandomatic URLs".
3.1. Relative URLs
URLs come in two flavors: absolute and relative. So far, we have looked only at absolute URLs. With an absolute URL, you have all the information you need to access a resource.
On the other hand, relative URLs are incomplete. To get all the information needed to access a resource from a relative URL, you must interpret it relative to another URL, called its base.
Relative URLs are a convenient shothand notation for URL. If you have ever written HTML by hand, you have probably found them to be a great shortcut. Example 2-1 contains an example HTML document with an embedded relative URL.

Example 2-1. HTML snippet with relative URLs
In Example 2-1, we have an HTML document for the resource:
http://www.joes-hardware.com/tools.html
In the HTML document, there is a hyperlink containing the URL ./hammers.html. This URL seems incomplete, but it is a legal relative URL, It can be interpreted relative to the URL of the document in which it is found; in this case, relative to the resource /tools.html on the Joe's Hardware web server.
The abbreviated relative URL syntax lets HTML authors omit from URLs the scheme, host, and other components. These components can be inferred by the base URL of the resource they are in. URLs for other resources also can be specified in this shorthand.
In Example 2-1, our base URL is:
http://www.joes-hardware.com/tools.html
Using this URL as a base, we can infer the missing information. We know the resource is ./hammers.html, but we don't know the scheme or host. Using the base URL, we can infer that the scheme is http and the host is www.joes-hardware.com. Figure 2-4 illustrates this.

Figure 2-4. Using a base URL
Base URls
The first step in the conversion process is to find a base URL. The base URL serves as a point of reference for the relative URL. It can come from a few places:
Explicitly provided in the resource
Some resources explicitly specify the base URL. An HTML document, for example, may included a <BASE> HTML tag defining the base URL by which to convert all relative URLs in that HTML document.
Base URL of the encapsulating resource
If a relative URL is found in a resource that does not explicitly specify a base URL, as in Exampel 2-1, it can use the URL of the resource in which it is embedded as a base (as we wid in our example).
No base URL
In some instances, there is no base URL. this often means that you have an absolute URL; however, sometimes you may just have an incomplete or broken URL.
Resolving relative references
Previously, we showed the basic components and syntax of URLs. The next step in converting a relative URL into an absolute one is to break up both the relative and base URLs into their component pieces.
In effect, you are just parsing the URL, but this is often called decomposing the URL, bacause you are breaking it up into its components. Once you have broken the base and relative URLs into their components, you can then apply the algorithm pictured in Figure 2-5 to finish the conversion.
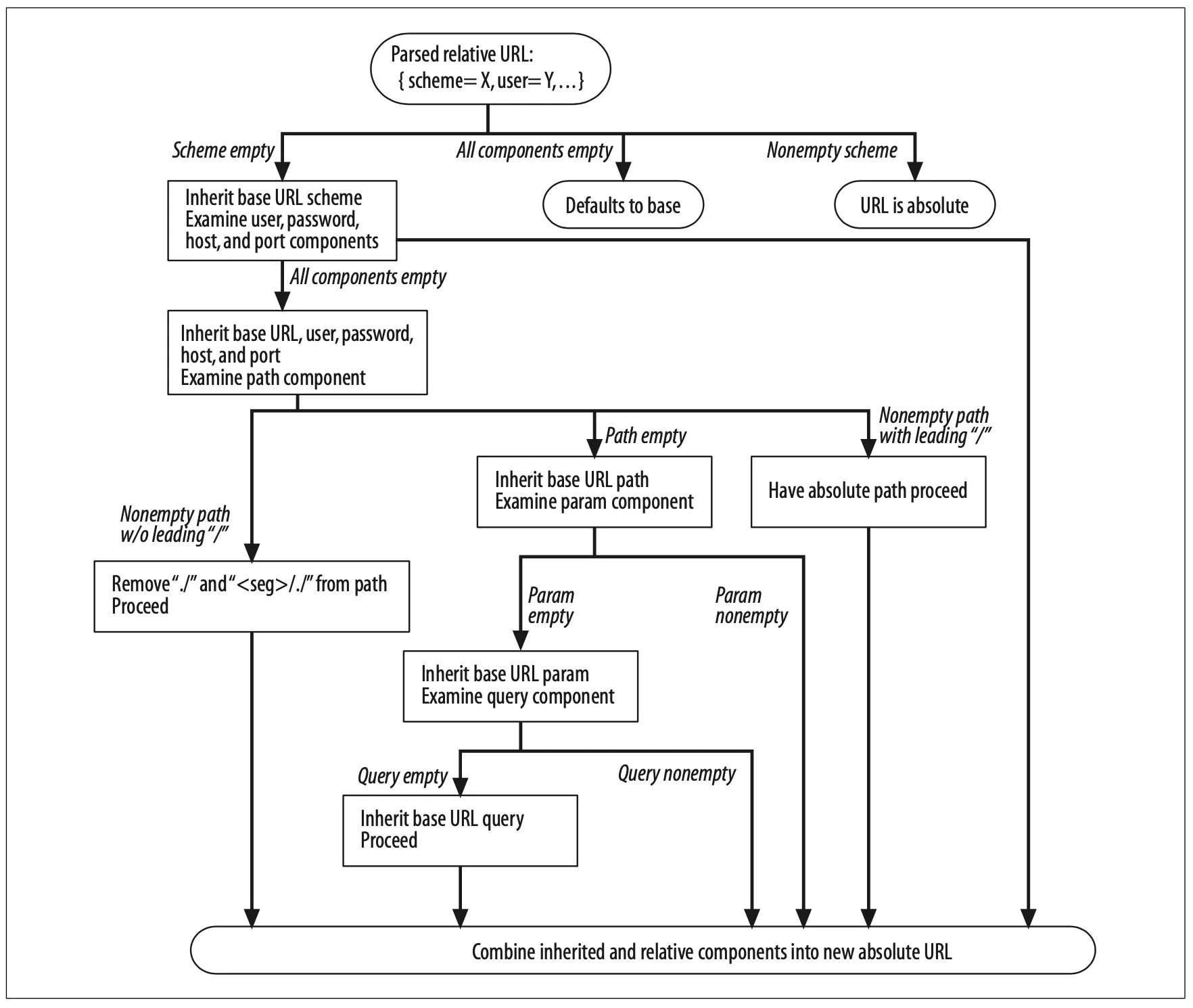
Figure 2-5. Converting relative to absolute URLs
This algorithm converts a relative URL to its absolute form, which can then be used to reference the resource. This algorithm was originally specified in RFC 1808 and later incorporated into RFC 2396.
With our ./hammers.html example from Example 2-1, we can apply the algorithm depicted in Figure 2-5:
1.
Path is ./hammers.html; base URL is http://joes-hardware.com/tools.html.
2.
Scheme is empty; proceed down left half of chart and inherit the base URL scheme (HTTP).
3.
At least one component is non-empty; proceed to bottom, inheriting host and port components.
4.
Combining the components we have from the relative URL (path: ./hammers.html) with what we have inherited (scheme: http, host: www.joes-hardware.com, port:80), we get our new absolute URL: http://www.joes-hardware.com/hammers.html.
3.2. Expandomatic URLs
Some browsers try to expand URLs automatically, either after you submit the URL or while you're typing. This provides user with a shortcut: they don't have to type in the complete URL, because it automatically expands itself.
These "exanddomatic" features come in two flavors:
Hostname expansion
In hostname expansion, the browser can often expand the hostname you type in into the full hostname without your help, just by using some simple heuristics.
For example if you type "yahoo" in the address box, your browser can automatically insert "www." and ".com" onto the hostname, creating "www.yahoo.com". Some browsers will try this if they are unable to find a site that matches "yahoo", trying a few expansions before giving up. Browsers apply these these simple tricks to save you some time and frustration.
However, these expansion tricks on hostnames can cause problems for other HTTP applications, such as proxies, In Chapter 6, we will discuss these problem in more detail.
History expansion
Another technique that browsers use to save you time typing URLs is to store a history of the URLs that you have visited in the past. As you type in the URL, they can offer you completed choices to select from by matching what you type to the prefixes of the URLs in your history. So, if you were typing in the start of a URL that you had visited previously, such as http://www.joes-, your browser could suggest http://www.joes-hardware.com. You could then select that instead of typing out the the complete URL.
Be aware that URL auto-expansion may behave differently when used with proxies. We discuss this further in "URI Client Auto-Expansion and Hostname Resolution in Chapter 6."
4. Shady Characters
This section let you understand why encoding is used for URLs. So I hope that learning it completely.
- Cheolho
URLs were designed to be portable. They were also designed to uniformly name all the resources on the Internet, which means that they will be transmitted through various protocols. Because all of the these protocols have different mechanisms for transmitting their data, it was important for URLs to be designed so that they could be transmitted safely through any Internet protocol.
Safe transmission means that URLs can be transmitted without the rist of losing information. Some protocols, such as the Simple Mail Transfer Protocol (SMTP) for electronic mail, use transmmssion methods that can strp off certain characters. To get around this, URLs are permitted to contain only characters from a relatively small, universally safe alphabet.
In addition to wanting URLs to be transportable by all Internet protocols, designers wanted them to be readable by people. So invisible, nonprinting characters also are prohibited in URLs, even though these characters may pass through mailers and otherwise be portable.
To complicate matters further, URLs also need to be complete. URL designers realized there would be times when people would want URLs to contain binary data or characters outside of the universally safe alphabet. So, an excape mechanism was added, allowing unsafe characters to be encoded into safe characters for transport.
This section summarizes the universal alphabet and encoding rules for URLs.
4.2. The URL Character Set
Default computer system characters sets often have an Anglocentric bias. Historically, many computer applications have used the US-ASCII character set. US-ASCII uses 7 bits to represent most keys available on an English typewriter and a few non-printing control characters for text formatting and hardware signaling.
US-ASCII is very portable, due to its long legacy. But while it's convenient to citizens of the U.S., it doesn't support the inflected characters common in European languages or the hundreds of non-Romanic languages read by billions of people around the world.
Furthermore, some URLs may need to contain arbitrary binary data. Recognizing the need for completeness, the URL designers have incorporated escape sequences. Escape sequences allow the encoding of arbitrary character values of data using a restricted subset of the US-ASCII character set, yielding portability and completeness.
4.3. Encoding Mechanisms
To get around the limitations of a safe character set representation, an encoding scheme was devised to represent characters in a URL that are not safe. The encoding simply represents the unsafe character by an "escape" notation, consisting of a percent sign (%) followed by two hexadecimal digits that represent the ASCII code of the character.
Table 2-2 shows a few examples.

Table 2-2. Some encoded character examples
4.4. Character Restrictions
Several characters have been reserved to have special meaning inside of a URL. Others are not in the defined US-ASCII printable set. And still others are known to confuse some Internet gateways and protocols, so their use is discouraged.
Table 2-3 lists characters that should be encoded in a URL before you use them for anything other than their reserved purposes.


Table 2-3. Reserved and restricted characters
4.5. A Bit More
You might be wondering why nothing bad has happened when you have used characters that are unsafe. For instance, you can visit Joe's hoem page at:
http://www.joes-hardware.com/~joe
and not encode the "~" character. For some transport protocols this is not an issue, but it is still unwise for application developers not to encode unsafe characters.
Applications need to walk a fine line. It is best for client applications to convert any unsafe or restricted characters before sending any URL to any other application. Once all the unsafe have been encoded, the URL is in a canonical form that can be shared between applications; there is no need to worry about the other application getting confused by any of the character's special meanings.
The original application that gets the URL from user is best fit to determine which characters need to be encoded.
